Высокотемпературный электронный термометр на ATTiny13, MAX6675 и TM1637

Решил сделать свою паяльную станцию и возник вопрос о её калибровке. Покупать на Али высокотемпературный точный измеритель температуры просто жаба задавила. Дома были в наличии простенькие микроконтроллеры ATTiny13 и четырёхразрядный дисплей на TM1637. А также завалялась пара аккумуляторов от электронных сигарет и термопара от мультиметра.
Поэтому решил сделать свой высокотемпературный электронный термометр, используя специализированную микросхему преобразователь для термопар K-типа.
Самая простая, которая была на Али, это MAX6675.
Заодно, решил проверить сколько кода нужно, по минимуму, для вывода данных на TM1637, если писать код без использования библиотек.
В качестве термопары используется хорошо знакомая версия для мультиметров. Цена на Али меньше трёх долларов за пару. Там именно термопара типа К, которая нужна для MAX6675.
На Али были куплены три микросхемы MAX6675 за четыре доллара. Там же был куплен пластиковый корпус размером 73 X 43 X 23 mm за доллар.
Микросхема MAX6675 имеет компенсацию холодного спая, что снимает эту проблему при измерениях с помощью термопары и даёт хороший по точности результат.
Немного помудрил со схемой, чтобы удобнее было собирать всё до кучи и ножки одной микросхемы удобно попадали напротив ножек другой.
В результате получилась такая схема:
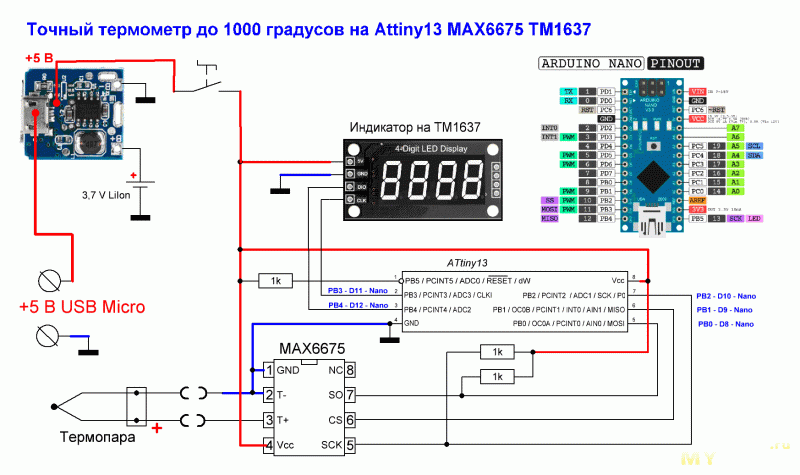
На схеме также указана распиновка Arduino Nano и её пины, к которым подключалась схема при тестировании кода с Arduino Nano вместо ATTiny13.
Код писался в Arduino IDE 1.8.19.
Размер скетча при компиляции получился 362 байта. Так что желающие могут попробовать нарастить функционал. Например, фиксация максимального напряжения. Или запись температуры в память по кнопке, которые поддерживаются TM1637, и индикация по вызову сохранённых значений. Звуковая индикация разных событий (тоже через TM1637) и т.д…
В качестве программатора использовал Arduino Nano, прошитый под ISP программатор. При попытке прошивки иногда выдавалась ошибка. Устранялась повторным запуском процесса прошивки. Два раза подряд ошибка ни разу не выскакивала.
Ядро использовалось MicroCore.
Настройки Arduino IDE при прошивке вот такие:
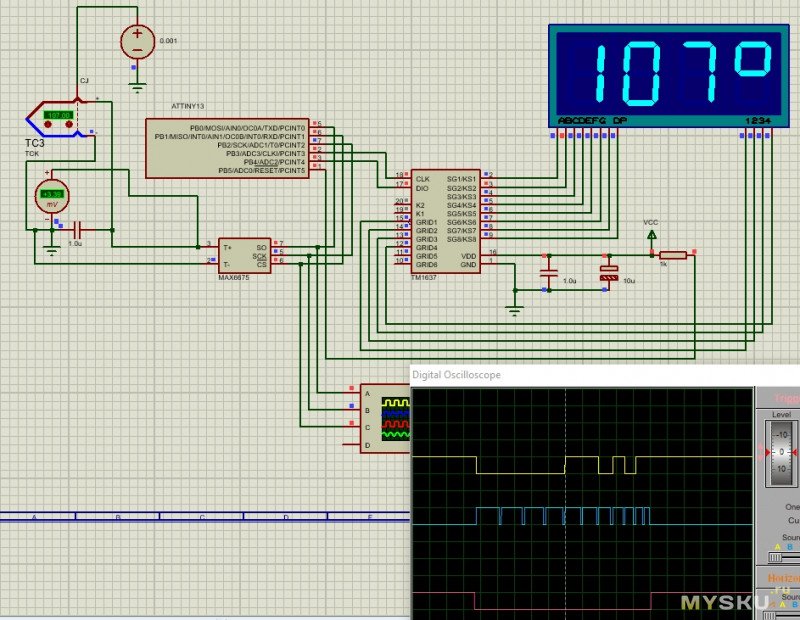
 Проверил написанный код с этой схемой в Proteus. Всё ОК.
Проверил написанный код с этой схемой в Proteus. Всё ОК.
 Спаял, прошил – не работает. ((
Спаял, прошил – не работает. ((
Заменил ATTiny13 на Arduino Nano. Прошил тем же кодом. Всё работает.
Путём проб и ошибок и с помощью осциллографа выяснил, что вся проблема в величине пауз между сигналами на входе TM1637. При слишком коротких паузах, TM1637 не успевает отрабатывать команды СТАРТ, СТОП и ЗАПИСЬ БАЙТА.
Подобрал правильные паузы. Заработало.
При проверке точности получилось, что прибор завышает показания примерно на три градуса (проверял по комнатной температуре, температуре тела и по кипящей воде).
Внёс поправку в код скетча на минус три градуса. Стал показывать точно 100 при окунании в кипящую воду, 36 градусов в качестве медицинского термометра и при сравнении с комнатной температурой по обычному термометру разбежность ушла. Вроде нормально, учитывая паспортную погрешность MAX6675.
При сравнении показаний от трёх термопар от мультиметров, расхождения между ними не превышали одного градуса. То есть даже дешевые термопары от мультиметров штука достаточно стабильная.
Потом решил сэкономить ещё чуток памяти контроллера и заменил паузы между сменами уровней на выходе контроллера просто повторными выдачами команд на установку нужного уровня сигнала на выходах контроллера, идущих к TM1637.
Получилось. Работает.
Теперь, с учётом этих нюансов, можно пробовать сделать паяльную станцию с дисплеем TM1637 на базе ATTiny13.
С монтажом решил не заморачиваться.
Всё паялось навесным монтажом с использованием переходников для микросхем контроллера и MAX6675.
Внутри корпуса всё крепилось на горячий клей.
Фото результата:
1. Температура в комнате

2. Вид внутри

3. Заряжаем от USBmicro

4. Моя температура тела

Код скетча прилагается:
P.S.
Спасибо комментаторам — заметили, что на схеме не указано соединение отрицательного провода термодатчика с минусом питания. На фото внутренностей это соединение видно, а на схеме забыл дорисовать. Сейчас уже поправил.
И также отметили, что в тексте не указано, что MAX6675 имеет компенсацию холодного спая.
Тоже добавил в тексте.
Поэтому решил сделать свой высокотемпературный электронный термометр, используя специализированную микросхему преобразователь для термопар K-типа.
Самая простая, которая была на Али, это MAX6675.
Заодно, решил проверить сколько кода нужно, по минимуму, для вывода данных на TM1637, если писать код без использования библиотек.
В качестве термопары используется хорошо знакомая версия для мультиметров. Цена на Али меньше трёх долларов за пару. Там именно термопара типа К, которая нужна для MAX6675.
На Али были куплены три микросхемы MAX6675 за четыре доллара. Там же был куплен пластиковый корпус размером 73 X 43 X 23 mm за доллар.
Микросхема MAX6675 имеет компенсацию холодного спая, что снимает эту проблему при измерениях с помощью термопары и даёт хороший по точности результат.
Немного помудрил со схемой, чтобы удобнее было собирать всё до кучи и ножки одной микросхемы удобно попадали напротив ножек другой.
В результате получилась такая схема:
На схеме также указана распиновка Arduino Nano и её пины, к которым подключалась схема при тестировании кода с Arduino Nano вместо ATTiny13.
Код писался в Arduino IDE 1.8.19.
Размер скетча при компиляции получился 362 байта. Так что желающие могут попробовать нарастить функционал. Например, фиксация максимального напряжения. Или запись температуры в память по кнопке, которые поддерживаются TM1637, и индикация по вызову сохранённых значений. Звуковая индикация разных событий (тоже через TM1637) и т.д…
В качестве программатора использовал Arduino Nano, прошитый под ISP программатор. При попытке прошивки иногда выдавалась ошибка. Устранялась повторным запуском процесса прошивки. Два раза подряд ошибка ни разу не выскакивала.
Ядро использовалось MicroCore.
Настройки Arduino IDE при прошивке вот такие:
Проверил написанный код с этой схемой в Proteus. Всё ОК. Спаял, прошил – не работает. ((Заменил ATTiny13 на Arduino Nano. Прошил тем же кодом. Всё работает.
Путём проб и ошибок и с помощью осциллографа выяснил, что вся проблема в величине пауз между сигналами на входе TM1637. При слишком коротких паузах, TM1637 не успевает отрабатывать команды СТАРТ, СТОП и ЗАПИСЬ БАЙТА.
Подобрал правильные паузы. Заработало.
При проверке точности получилось, что прибор завышает показания примерно на три градуса (проверял по комнатной температуре, температуре тела и по кипящей воде).
Внёс поправку в код скетча на минус три градуса. Стал показывать точно 100 при окунании в кипящую воду, 36 градусов в качестве медицинского термометра и при сравнении с комнатной температурой по обычному термометру разбежность ушла. Вроде нормально, учитывая паспортную погрешность MAX6675.
При сравнении показаний от трёх термопар от мультиметров, расхождения между ними не превышали одного градуса. То есть даже дешевые термопары от мультиметров штука достаточно стабильная.
Потом решил сэкономить ещё чуток памяти контроллера и заменил паузы между сменами уровней на выходе контроллера просто повторными выдачами команд на установку нужного уровня сигнала на выходах контроллера, идущих к TM1637.
Получилось. Работает.
Теперь, с учётом этих нюансов, можно пробовать сделать паяльную станцию с дисплеем TM1637 на базе ATTiny13.
С монтажом решил не заморачиваться.
Всё паялось навесным монтажом с использованием переходников для микросхем контроллера и MAX6675.
Внутри корпуса всё крепилось на горячий клей.
Фото результата:
1. Температура в комнате
2. Вид внутри
3. Заряжаем от USBmicro
4. Моя температура тела
Код скетча прилагается:
// Точный термометр до 1000 градусов на ATTiny13 с MAX6675 и TM1637
// есть отображение значка градусов в 4-ом разряде
//
// Скетч использует 362 байт (35%) памяти устройства. Всего доступно 1024 байт.
// Глобальные переменные используют 0 байт (0%) динамической памяти, оставляя 64 байт для локальных переменных. Максимум: 64 байт.
// Обновление данных 1 раз в секунду.
// Усреднение по четырём замерам
// Значёк градуса в правом разряде дисплея
// В коде поправка на -3 градуса - при этом точность температуры в комнате, температуры тела и температуры кипения воды - до одного градуса
#include <avr/io.h>
#include <avr/pgmspace.h>
#include <util/delay.h>
// Определить пины для кодключения к МАХ6675
#define miso PB0 // MAX6675 MISO - 5 ножка ATtiny13
#define cs PB1 // MAX6675 CS - выбор микросхемы - 6 ножка ATtiny13
#define clk PB2 // MAX6675 CLK - 7 ножка ATtiny13
// Определить состояние пинов для кодключения к TM1637
#define DIO_H() (PORTB |= _BV(PB4))
#define DIO_L() (PORTB &= ~_BV(PB4))
#define DIO_OUT() (DDRB |= _BV(PB4))
#define DIO_IN() (DDRB &= ~_BV(PB4))
#define DIO_RD() (((PINB & _BV(PB4)) > 0) ? 1 : 0)
#define CLK_H() (PORTB |= _BV(PB3))
#define CLK_L() (PORTB &= ~_BV(PB3))
//------------- ¤ркость свечени¤ индикатора TM1637 ----------
#define Bright0 0x88
#define Bright1 0x89
#define Bright2 0x8A
#define Bright3 0x8B
#define Bright4 0x8C
#define Bright5 0x8D
#define Bright6 0x8E
#define Bright7 0x8F
#define SetBright Bright5 //сюда прописать ¤ркость от 0 до 7. По умолчанию 5.
//------------------------------------------------------------------
// Коды цифр 0-9, пусто и значка градуса для сегментов (A-B-C-D-E-F-G)
const uint8_t digits[] PROGMEM =
{
// Соответствие разрядов и сегментов
0x3F, // 0 - B00111111
0x06, // 1 - B00000110
0x5B, // 2 - B01011011
0x4F, // 3 - B01001111
0x66, // 4 - B01100110 _1_
0x6D, // 5 - B01101101 6 | | 2
0x7D, // 6 - B01111101 |_7_|
0x07, // 7 - B00000111 5 | | 3
0x7F, // 8 - B01111111 |_4_|
0x6F, // 9 - B01101111
0x00, // пусто - B00000000
0x63 // градус - B001100011
};
//********************************************************************************************************
//*************************** SETUP *****************************************************************
int main(void)
{
//=================== Инициализация дисплея ===================
DDRB |= (_BV(PB4)|_BV(PB3)); // Настройка PB3 и PB4 на выход
PORTB &= ~(_BV(PB4)|_BV(PB3)); // Установка PB3 и PB4 в ноль
delay_msTK(100);
#if F_CPU != 9600000UL
#error "Частота в коде не совпадает с настройками IDE!"
#endif
//********************************************************************************************************
//********************* ОСНОВНОЙ ЦИКЛ ******************************************************************
while(1)
{
int t = getSmoothTemp(); //Читаем усреднённые данные из модуля термопары MAX6675 и ...
if (t > 3) // ... вычитаем поправку (у меня выдавал без поправки на три градуса больше)
t = t - 3;
byte ks = 0;
byte kd = 0;
while (t>=100)
{
t-=100;
ks++;
}
while (t>=10)
{
t-=10;
kd++;
}
//************ Выводим число на индикатор *******************
if (ks==0)
ks=10;
// 1. Команда установки данных (0x40 - автоинкремент адреса)
start();
writeByte(0x40);
stop();
// 2. Установка адреса начала (0xC0) и передача 4 цифр
start();
writeByte(0xC0);
writeByte(pgm_read_byte(&digits[ks])); // Первая цифра
writeByte(pgm_read_byte(&digits[kd])); // Вторая
writeByte(pgm_read_byte(&digits[t])); // Третья
writeByte(pgm_read_byte(&digits[11])); // Четвертая
stop();
// 3. Установка яркости (0x88 - включено, средняя яркость)
start();
writeByte(SetBright);
stop();
delay_msTK(100); // задержка
}
}
//********************* КОНЕЦ MAIN ******************************************************************
//*****************************************************************************************************
//*****************************************************************************************************
//*****************************************************************************************************
//********************* ФУНКЦИИ *********************************************************************
//------------------------------------------------------
//--------- Функция отправки одного байта ------------
void writeByte(uint8_t value)
{
uint8_t i;
for (i = 0; i < 8; ++i)
{
CLK_L();
if (value & 0x01)
DIO_H();
else
DIO_L();
value >>= 1;
CLK_H();
}
CLK_L();
DIO_IN();
DIO_IN();
CLK_H();
DIO_OUT();
}
//------------------ Команда СТАРТ --------------------
void start()
{
DIO_H();
CLK_H();
CLK_H();
CLK_H();
DIO_L();
}
//------------------ Команда СТОП ---------------------
void stop()
{
CLK_L();
DIO_L();
DIO_L();
DIO_L();
CLK_H();
DIO_H();
}
//=== Своя функция задержки в мс ====================
void delay_msTK(uint8_t ms)
{
while(ms--)
_delay_ms(1);
}
//******************** Усреднение по 4 замерам для стабильности показаний ***********************
int getSmoothTemp()
{
int sum = 0;
for (int i = 0; i < 4; i++) // В цикле суммируем показания 8 опросов ...
{
sum += spiRead() ; // ... в переменную sum
delay_msTK(240); // Делаем паузу между опросами - MAX6675 нужно время на преобразование 170 - 220 мс
}
return (sum >>= 2); // Делим показания на 4 - получаем усреднённое значение
}
//*************************** Чтение данных из модуля термопары MAX6675 ******************************
//https://arduinodiy.wordpress.com/2019/12/06/using-a-max6675-temperature-sensor-without-a-library/
int spiRead()
{
DDRB = DDRB | 0B00000110;
int rawTmp = 0;
PORTB &= ~(1<<cs); // cs,LOW
delay_msTK(2); // задержка 2 миллисекунды
PORTB |= (1<<cs); // cs,HIGH
delay_msTK(200); // задержка 200 миллисекунд
PORTB &= ~(1<<cs); // cs,LOW Опускаем CS для старта преобразования
//Считываем 11 из 14 бит из MAX6675 и сохраняем в rawTmp
//(больше не нужно - 11 бит это целая часть температуры без точнсти 0,25 градусов)
for (int i=10; i>=0; i--)
{
PORTB |= (1<<clk); // clk,HIGH
byte r=0;
if(PINB & (1<<miso)) // Чтение пина MISO - если на ножке MISO 1, то ...
r=1; // ... фиксируем единичку
rawTmp +=r << i; // Сохраняем считанный бит в переменную температуры
PORTB &= ~(1<<clk); // clk,LOW
}
PORTB |= (1<<cs); // cs,HIGH
return rawTmp;
}
//=========================================================================================================
P.S.
Спасибо комментаторам — заметили, что на схеме не указано соединение отрицательного провода термодатчика с минусом питания. На фото внутренностей это соединение видно, а на схеме забыл дорисовать. Сейчас уже поправил.
И также отметили, что в тексте не указано, что MAX6675 имеет компенсацию холодного спая.
Тоже добавил в тексте.
Самые обсуждаемые обзоры
Автору, конечно респект, но вид, конечно… Строго 18+!!!
Плюс програмирование, хорошая зарядка для мозга. У меня дед до старости задачки решал и пазлы складывал.
— была в наличии часть комплектующих
— нужен был прибор для калибровки
— нужно было проверить, сколько кода займёт обмен с TM1637 для дальнейшего применения такого индикатора с этим контроллером в паяльной станции
И так пойдёт. У нас тут куча адептов, что датчик температуры в ручке паяльника (для компенсации холодного спая) не нужен. :)
Комнатная температура не сильно отклоняется от этого значения.
И корректировать нужно не на температуру в комнате, а на температуру ручки. Когда много паял, моя нагревалась заметно (теплее чем ладонь)
Ну и на синем сайте 624р:
Мне мой обошелся дешевле.
Он меньше по размерам.
Нет проблемы со считыванием информации при пониженой освещённости.
Работает от аккумулятора и подзаряжается обычной телефонной зарядкой.
Есть возможность доработки программы под дополнительные хотелки.
В отличие от приведённого на Вашем фото, может использоваться не только для замера температуры жала паяльника.
Ну и точный, компактный высокотемпературный термометр в хозяйстве всегда пригодится. ))
Учитывая остаток свободного места у ATTiny13, можно доработать до высокотемпературного терморегулятора или сигнализатора высокой температуры.
Или там обычное измерение микровольт?
а отдельная микросхема — нафига? это она калечному ацп тиньки нужна, а не специализированным для мультиметров.
Дальше будет хуже из-за нелинейности термопары. А-ля 830-е не умеют учитывать нелинейность термопар. ))
Поэтому ожидать от наобум взятого мультиметра высокой точности явно не следует.
(Мне тут впервые за тридцать лет понадобилось измерять температуру более-менее точно, и именно мультиметром. А он десять лет назад делал это нормально, а сейчас, как оказалось, врёт безбожно. Вот и сижу, смотрю на его плату и чешу затылок — как же, не имея второго мультиметра, найти именно те два подстроечника, которые за термопару отвечают.)
И добавить какой-то ещё функционал в свой прибор я могу (например сохранение нескольких контрольных замеров по дополнительной кнопке или вывод показаний по Фаренгейту, или Кельвину, или превратить его в терморегулятор и т.д.), а Вы в свой мультиметр не сможете.
К тому же мультиметры без микроконтроллеров, с обычными вариантами а-ля ICL7106 не учитывают нелинейность характеристики термопары.
А она там есть. Вот для справки.
«Термопара имеет нелинейную характеристику. Зависимость между температурой рабочего спая и напряжением (термо-ЭДС), которое вырабатывает термопара, не является прямой линией (напряжение растет не пропорционально температуре).Ключевые особенности нелинейности: Большинство промышленных термопар (типы K, S, J, L и др.) имеют выраженную нелинейность, которая меняется в зависимости от измеряемого диапазона температур.
Причина: Эффект Зеебека сам по себе нелинеен, и величина термо-ЭДС зависит от разности температур горячего и холодного спаев. Как это учитывается: Для точных измерений приборы (вторичные преобразователи, контроллеры) используют специальные алгоритмы линеаризации, таблицы или полиномы для преобразования нелинейного напряжения в точную температуру.»
А где написано, что MAX не обрабатывает данные термопары для повышения точности?
Вот что говорит Алиса:
Qwen того же мнения:
Ну и цена у него не слабая.
У меня такого нет.
Поэтому мне проще сделать свой прибор за недорого с такой же точностью. ))
Если показания не совпадают — либо поддельная термопара, что встречается при покупке ее отдельно когда родную от мультиметра сломали или потеряли, либо «игрушечный» некалиброванный мультиметр
P.S. Ничего не имею против DIY, отвечаю лишь на сообщение о невозможности нормально измерять температуру мультиметром.
Те, что не на контроллерах, а на простых АЦП типа 7106, не отличаются точностью.
10 — клон Хакко и пяток датчиков в комплекте — www.aliexpress.com/ssr/300000512/BundleDeals2?productIds=1005012013884820%3A12000057287106823
Пределы там, правда, 600 и 700 градусов заявлены, но для паяльной станции — с головой
Edit: теперь оно меня ими спамит… Вот за 3.45: https://www.aliexpress.com/item/1005008703344868.html — и всё это именно для паяльника, с соответствующим креплением датчика.
Само устройство 12.31
Неясна конечная цель.
Тм-902С решает задачу по приемлемой стоимости
Чтобы ТХА работала до 1200°С, ее нужно как-то упаковать — это главная проблема, с чем я, например, бился лично ) стандартные термопары типа К упакованы в нерж футляр из 304, который и ограничивает Т применения на уровне градусов 800°С.
Мне мой обошелся дешевле.
Он меньше по размерам.
Нет проблемы со считыванием информации при пониженой освещённости.
Работает от аккумулятора и подзаряжается обычной телефонной зарядкой.
Есть возможность доработки программы под дополнительные хотелки.
При том, что платина-родий для моих применений очевидно избыточна. Плюс, если правильно припоминаю — платинородиевым же нужен газовый поддув нейтральным газом, чтобы не происходило отравления и выгорания? Это не для бытового применения.
Сам когда писал либу под MAX31855 — github.com/enjoyneering/MAX31855. Меня тогда очень просили добавить линеаризацию термопары. Внезапно микруха этого сама не умеет. Вобщем вам есть еще чего добавить, чтобы вообще шик-блеск.
Кстати для усреднения очень хорошо работает медианный фильтр на 3 измерения. Пример тут — github.com/enjoyneering/HCSR04
Одна дополнительная команда в коде решила проблему неустойчивого обмена данными.
Эти конденсаторы нужны при работе с устройствами создающие большие помехи, типа коллекторных двигателей и тд.
За див конечно плюс
Докупались только корпус и MAX 6675.
Итого 2,5 бакса затрат.
При 770 мм рт. ст.: примерно \(100,37^\circ\text{C}\).
При 750 мм рт. ст.: примерно \(99,63^\circ\text{C}\).
Как видно из этих данных, изменение давления на каждые 10 мм рт. ст. от нормального (760 мм рт. ст.) меняет точку кипения примерно на \(0,37^\circ\text{C}\) в соответствующую сторону.
Вот, например, для Москвы сегодня давление 742 мм рт.ст., моя квартира примерно на 40-50 метров выше базовой погодной станции, если верить навигации, карте высот и яндексу. Т.е у меня должно быть примерно 738 мм рт.ст., что даёт около 99.16 градусов кипения воды. Ближе к 99, чем к 100.
Хотя при точности МАХ в 2 градуса толку от такой калибровки мало. Но… Когда-то я пытался по воде откалибровать свою схему тоже, поверенный прибор показывал 99.2-99.4 температуру кипящего чайника. Вот и вспомнилось к случаю. :)
Но это я так, подушнить в качестве развлекательного чтения.
Давление бортовой компьютер машины показывает 992 мбар. Это 744 мм.
613 рублей в Озоне… И тут мне вспомнился пошлый анекдот про размеры и форму огурчиков… «Мне без разницы форма и размеры — мне их в окрошечку»… Сколько времени у меня уйдет на ожидание комплектухи, поиски всякой всячины для комплекта, пайку, программирование… Я за час зарабатываю больше, чем стОит готовый прибор! Я лучше потрачу свободное время на более полезные дела, с теми же Ардуинками более интересные и нужные проекты…
Каждый тратит свободное время как хочет.
Меня мой вариант времяпрепровождения вполне устраивает. ))
в смысле?
По-моему автор заслуживает похвалы за разработку, а он почему-то вынужден оправдываться…
ну так его аргументация критики не выдерживает.
но зачем она вообще нужна — непонятно, захотел — сделал.
У меня при разработке была такая:
— была в наличии часть комплектующих
— покупать готовый было дороже
— готовое решение невозможно доработать, при необходимости
— нужен был прибор для калибровки
— нужно было проверить, сколько кода займёт обмен с TM1637 для дальнейшего применения такого индикатора с этим контроллером в паяльной станции
но если так хочется поспорить, то во1ых готовый таки дешевле, во2ых сама идея калибровки паяльника практического смысла не имеет, равно как и изобретения велосипеда в этой (ейный контроллер) области — тоже, ибо их полно готовых и тоже — дешевле.
Ссылочку дадите на покупной за 4 доллара?
Ссылочку на паяльную станцию с цифровым дисплеем и ценой до 10 долларов дадите?
А если Вам не нравится точное отображение температуры жала на дисплее, то это только Выша личная проблема. Не нужно за всех делать подобные заявления. ))
Мне достаточно было примера, когда паяльная станция GVM T12-XS за сорок долларов, свежепривезённая из магазина, врала более, чем на 30 градусов.
https://www.ozon.ru/product/tm-902c-portativnyy-udobnyy-izmeritel-temperatury-k-tip-zhk-tsifrovoy-termometr-termopara-zond-1300-4108968321
контроллер — 600р:
https://www.ozon.ru/product/youlort-payalnik-75-vt-keramicheskiy-nagrevatel-1281909521
мне на него пофиг, а с подобного бессмысленного перфекционизма — смешно.
И контроллера паяльной станции дешевле 10 долларов там тоже нет.
А на тиньке и TM1637 контроллер обойдётся в пять баксов. Так что Ваш пример с Озона всё равно дороже — 8 у.е.
Ну, а если Вас не смущает ошибка паяльной станции более 30 градусов, то я же не настаиваю — работайте и такой.
Я предпочитаю поточнее.
Программировать в среде Wiring на «чистом C» — своеобразное эстетство. Сам порой балуюсь.
«Потому что могу».
Очень красивый проект.
смысл правда сильно не очевиден, ибо в плюсах безотносительно всякого обьектного есть удобные конструкции.
у автора странное только про цены.
Хотя в молодости и в кодах 580-го процессора напрямую приходилось кодить. ))
Со всей математикой, с выводом в текстовую таблицу для бухгалтерии, все дела…
Это, видимо, моё личный рекорд несоответствия инструмента задаче )))
Да уж — были времена.
И всё это без помощи ИИ. ))
Единственное, поддерживать такой продукт труднее.
Если Вы (вдруг) не в курсе, типичная процедура инсталляции FreeBSD заключается в формировании конфигурационного файла и последующей компиляции ВСЕЙ системы под конкретную машину прямо на ней же.
Но тут сама задача и не требовала компиляции вовсе, можно было писать хоть на Бейсике.
Надо всего лишь отпарсить текстовый лог-файл сендмейла за месяц, выбрать из него нужные данные, разложить по юзерам, пересчитать в объёмы, перемножить на цены и выдать табличку для бухгалтерии, будет оно при этом считаться 5 секунд или два часа — не имеет значения.
Буквально парой лет позже намного более сложный биллинг реального времени для карточного дайлапа я написал на перле, который для этих целей подходит просто идеально, и система успешно работала много лет, до физической кончины дайла у этого ИСП.
Когда в нашем городке частные компании начали переходит с дайлапа на постоянные подключения, безлимита поначалу не было и платили за объем. У нас в компании (где я тогда работал) решили разрешить сотрудникам доступ к интернету, но брать с них деньги за скачанный объем, поэтому возникла задача создать инструмент, который бы этот объем считал. Я также написал на перле анализатор логов WinGate, что задачу решило. Однако подсчет логов за месяц занимал несколько минут, из-за чего я не мог выложить это решение в публичный доступ и разрешить всем сотрудникам самостоятельно смотреть, сколько они потратили. Тогда я переписал анализатор на С++ используя memory mapped file и оптимизированный подсчет, что сократило время его работы до 10-15 секунд!
Но при этом такие откомпилированные программы всё равно будут менее производительны, чем программы, написанные на нормальных компилируемых языках, из-за больших накладных расходов, вызванных изначальным наличием в исходных языках особенностей, характерных для интепретируемых языков.
На что перлу достаточна одна строка, в бейсике потребует пару станиц.
Я писал тот биллинг на коленке и сам, один. Собсна, и весь узел собирал сам))
Раз в минуту один перловый скрипт через rlogin опрашивал поочерёдно все модемные пулы, сделанные на роутерах Cisco 3640, — «кто сейчас на линии», складывал в файловый буфер, всего было около 200 модемов, подключенных потоками ISDN PRI.
Другой скрипт брал из буфера, парсил, и для каждого активного юзера проверял в базе на мыскле его тарифный план, вычитал из остатка его баланса стоимость минуты в соответствии с временем суток по тарифному плану, и если вдруг остался ноль или появился административный запрет (оператор отключил юзера) — ставил на него флаг третьему скрипту, который заходил через rlogin на нужную киску и отключал юзера.
При подключении юзера киска запрашивала доступ для него у радиуса, который адресовался к четвёртому скрипту, тот проверял в той же базе на мыскле, есть ли такой юзер, не запрещён ли административно, хватит ли у него денег на балансе хотя бы на минуту работы в соответствии с его тарифным планом и временем, и выдавал или не выдавал разрешение радиусу, а тот — модемному пулу.
Там же крутились два простеньких веб-интерфейса на том же перле, один административный, для ввода/удаления/пополнения баланса операторами, другой — юзерский, для текущего контроля.
Карты вводились в базу пачками по 100 штук, были и индивидуальные аккаунты по договорам, вводились, понятно, по одному.
Всё это работало на двух самосборных p266, на одном — мыскль и радиус, на другом — собственно биллинг и веб-морды.
На каком-то из них крутились ещё и сендмейл для всех желающих, и МРТГ (а он тоже на перле) для рисования в рил-тайме красивых графиков загрузки модемных пулов, каналов и пр.
Всё — под FreeBSD.
И замечательно, с огромным запасом хватало производительности этих двух дохлых петухов на ежеминутный, напоминаю, контроль, вообще никакой потребности что-то переписывать более оптимально не возникало.
А, ещё примерно на такой же железке отдельно был собран BGP-роутер с брендмауэром и шейпером, тоже под фрями, я ж честно получил в райпе под этот узел AS и блок IP-адресов ))
Сиску :) Как бы это по-русски не звучало двусмысленно, но произносится именно так.
И начиная, как минимум, с тех же P266 обработка любого лога построчно выполняется быстрее, чем его чтение с диска — хоть на ассемблере, хоть на перле.
В моём опыте это так.
Хыыы… полагаете, я не в курсе? )))))
И не забывайте, что перл силен регулярными выражениями, которые легко обрабатывают логи, но тяжело даются процессору, это и объясняет скорость обработки.
Полагаю, вы же пишете иначе )
На перле тоже можно писать очень по-разному. Я, повторю, не замечал проблем со скоростью обработки логов. Вообще. И никогда такого не было, чтобы результата приходилось ждать «несколько минут».
Пишу так, как в ту пору принято было их называть среди посвящённых ))
Посвященных во что? В незнание английского? ) В ту пору их называли, в основном, «Циско», что еще можно понять, т.к. английская С во многих сокращениях по какой-то причине произносилась как Ц. Например, MSVC (Microsoft Visual C) — «МСВЦ». Также была еще одна легенда, что Cisco — это окончание San-Francisco, а раз у нас это произносится как «Сан-Франциско», значит, и Cisco надо читать «Циско».
А вот произношение «Киска» считалось мерзко-издевательским, когда маршрутизаторы пытались сравнивать с теми самыми «мокрыми кисками», которых можно было тогда полно найти в интернете. Неужели именно эту предметную область вы и назвали «для посвященных»? ))
Пишите регулярки удобно для транслятора — и не будет великой разницы.
Ничоси, Вас понесло )))
Киска — скорее, снисходительно-уменьшительно-ласкательное, как к симпатичной, но вредной и взбалмошной любимой девушке.
Про «незнание английского», а заодно и прямых указаний Создателя, расскажете тем, кто пишет «линуХ» )))
Что касается линуха — это прижившийся жаргон (к сожалению?). Также как «лухури», например.
То есть, разница тут в том, что в одном случае человек ошибся и прочитал неправильно, а в другом — исказил намеренно.
Среди тех айтишников /и названия-то такого ещё не было/, с кем я тогда активно общался и кого назвал «посвящёнными» /ибо очень мало нас тогда ещё было, и общались преимущественно, не поверите, — в фидонете )))/ это был ровно такой же типовой жаргон, как сейчас «линуХ».
Хотя, справедливости ради, были и поборники «чистоты языка», ага, и версию про Сан-Франциско тоже видел.
Между прочим, были несколько случаев, когда экспаты, — и нативные американцы, и всякие разные другие, — с которыми приходилось общаться на эту тему, замечательно понимали, о чём идёт речь, если по привычке говорил «киска» )))
Касательно сиски, в наших краях её повсеместно звали «циска». «киска» я слышал только от тех, кто не умел правильно читать название, либо когда был намек на неиллюзорные половые отношения с её конфигурацией в виде длительного и мучительного пердолинга последней. И, предположительно, второй вариант использования пошел от первых — кто-то неправильно прочитал, другим понравилось.
Это какая-то местная специфика, похоже.
Да и чего там пердолить?
Мне они вообще с первого взгляда вкатили — всем, кроме цены )))
Документация у них с самого начала была очень грамотная и качественная, да и альтернативы во многих случаях в те времена не было в принципе.
Помню, как восхитился идеей интерливинга, — когда году в 1997, если не путаю, мы пытались в один обычный телефонный спутниковый серийный линк на 64 кбод вструмить 4 канала VoIP и параллельно передачу данных, чтобы на дальнем объекте организовать электронную почту впридачу к телефону, и это удалось))
И называли их не только кисками, но и кошками, и вовсе не было в этом негативной коннотации — какой вообще может быть негатив к кошкам?
Те самые «мокрые киски» сами по себе результат незнания английского, ибо «pussy» означает совсем не «кошечка».
Что интересно, как минимум в восьмидесятые в народе употреблялся именно правильный перевод этого слова. Но, наверное, никто не подозревал, что это перевод, потому что очень уж по-русски оно звучало.
Соответственно, в описаниях порнофильмов для «pussy» гораздо более уместным и точным переводом, чем «киска», является «мохнатка».
А для многих прочих случаев — «пушистик».
Хороший умный программист, разумеется, на ассемблере сделает лучше, чем сможет компилятор.
Но много ли может сделать один хороший умный программист?
А при масштабном производстве, когда задачу приходится разбивать на множество частей для множества разных людей с разными навыками и мозгами, использование компилятора легко может дать лучший результат.
Но есть места, оптимизация которых дает огромный прирост. Например, мы решали одну задачу где нам надо было выводить масштабированный растр. Мой коллега сделал это по пикселям — цикл, цикл, вычисление адреса пикселя, вывод. Код был простой и понятный, но давал практически два кадра в секунду. Тогда пришел я, переписал это на ассемблер х86, добавил MMX для коррекции растра на лету, подняв производительность до сотни (емнип) кадров в секунду.
Связь простая — 50 пользователей по 2 минуты — это уже 100 минут. Каждый пользователь дергал сервис раза 3 в день, это 5 часов пустой работы процессора. А сервер должен был еще другие задачи выполнять, интернет он раздавал «постольку поскольку». Ну, и если сразу 2-3 человека ткнут в сервис, результата вообще никто не получал, отваливалось по таймауту.
Позже я так и сделал, когда нагрузка даже от сишного кода стала мешать основным функциям сервера. Но я же здесь не архитектуру обсуждаю, а сравнение быстродействия перла и си.
Виндовый перл — тот ещё перл, форки какие-то липовые, пайпы вообще нерабочие, да и в целом всё через ж.
Как минимум, так было четверть века назад )))))
А вот о быстродействии перла тех лет сказать ничего не могу, не помню. Использовали, кажется, ActiveState Perl 5. Но, правда, ни форков, ни пайпов при обработке логов не было.
Работу строил на FreeBSD, это вообще другая система, другая команда (название как бы намекает на Berkeley Software Distribution) и другая история, намного более древняя и фундаментальная, чем линух.
В 2000 году линух был ещё довольно сырой наколенной поделкой /на мой взгляд, канеш/, а BSD — серьёзной системой с серьёзным бэкграундом.
Я могу, сравнивал всяко-разно, отстой был полный на виндах.
Так её тоже никто у нас тогда не умел ни то что админить, даже просто установить) Но и, справедливости ради, задач под неё не было.
«Если вы в чём-то не разбираетесь, но хотите разбираться, начните разбираться — и разберётесь» )))
Так не надо было, я ж два раза сказал) Изначально сервер создали даже не из-за сетевой шары, а из-за менеджера лицензий какого-то софта, который проверял аппаратный ключ и раздавал лицензии по сети. А уже потом сделали шару, подключили принтер, научили раздавать интернет и т.п.
Так вот, менеджер лицензий этот был только под винду, т.к. сам софт был тоже только под винду.
Ну, и даже если бы сервер подняли на FreeBSD, разбираться с её админством заняло бы гораздо больше времени. То есть, было бы экономически невыгодно для организации.
Вот:
Уверен, что при желании Вы легко найдёте и саму эту аудиозапись.
А для себя?
А чисто из инженерного любопытства?
Просто чтобы быть в курсе и саморазвития для.
Не было его) Тогда настроить раздачу интернета — уже был успех. Интерес к линуксу (уже линуксу) у меня появился сильно позже, году в 2013, когда мы с товарищем подняли на собственном сервере небольшой сайт со скриптами и БД с нуля. Позже, по собственной инициативе, я перевел сайт компании с платного хостинга (такая услуга) на VPS.
Нажал юзер кнопочку «посчитать» на веб-морде, через «несколько минут» получил в почту файлик с итогом, в чём проблема?
Или сделать запуск по крону раз в час с расчётом для всех, а по запросу юзера выдавать ему его цифру с точностью до последнего часа, «по состоянию на 13.00».
Да, первые компиляторы Паскаля были ох и ах. Однако среда ТурбоПаскаль сделала язык столь популярным, что гиганты просто не могли пройти мимо поля непаханного. Дальше от версии к версии компиляторы становились сильно умнее.
Си — изначально «надстройка над ассемблером». Он НЕ МОГ работать медленнее. Вот не всегда экстремально идеально — да, матёрый ассемблерщик всегда мог выкроить пару килобайт или сотню тактов, переписав на ассемблере. Поэтому Кёрниган с первой минуты имел в линии языка обязательную поддержку инлайн-вставок инструкций ассемблера. С первых же минут, с нулевой версии.
Вы смотрели код, который выдает компилятор? Я смотрел. Во всех компиляторах и под все платформы, с которыми работал. И впечатлил меня только IAR под ARM — вот он реально генерировал крутой код, который было тяжело побить ассемблером. Но, тем не менее, свое демонстративное Radix-4 FFT компания ST (производитель STM) написала на ассемблере.
Да, я всегда смотрю код. На всех платформах. И меня, например, притно удивил код, который компилируется из C++ под AVR.
У первых компиляторов C никакой оптимизации не было. Хотя бы потому, что компиляторы эти писали те самые люди, которые этот язык сочиняли. А у них для этого не было времени — их производственным заданием было написать («быстренько склепать») операционную систему для компьютера, создаваемого в это время той фирмой, в которой они трудились.
С точки зрения возможности получения эффективного кода между Pascal и C нет никакой разницы. Вообще никакой. (Если, конечно, исключить из рассмотрения компиляцию для DEC-овских процессоров ;-) )
Сейчас уже мало кто помнит, но у некогда у Microsoft были компиляторы с Fortran, Pascal и С. А фактически это был один и тот же трёхпроходный компилятор, потому что второй (оптимизация) и третий (кодогенерация) проходы у них были общие, различался только первый проход (синтаксический разбор).
Возможно, у нас разное понимание качества ассемблерного кода, потому что я начинал программировать с ассемблера Z80, потом был ассебмлер х86 и только потом паскаль и си. И я всегда обращал внимание, насколько плохой код выдавали компиляторы и всегда понимал, как его можно сделать лучше.
Это лишь подтверждает предыдущий абзац, потому что я еще не видел, чтобы компилятор генерировал хороший код для АВР. А уж на АВР у меня много ассемблерных проектов.
Ассемблер это компилятор с некоторого языка, в котором машинные команды записываются текстом.
При этом для одних и тех же машинных команд может быть несколько разных способов их текстовой записи и, соответственно, несколько разных ассемблеров. (Примеры хорошо известны.)
Си — не надстройка над другим компилятором, а самостоятельный компилятор. И поэтому его встроенный язык ассемблера может иметь свой собственный, ни на что другое не похожий синтаксис.
Дальше есть компилятор Си, он берет на вход текстовые файлы, а на выходе выдает (условно) машинные коды. И как бы он не старался, он не сможет выдать решение более оптимальное, чем А, потому как А является самым оптимальным решением. А вот хуже выдать вполне может. То есть высказывание:
Ложное.
Представьте, что есть две машинные команды: X и Y — абсолютно друг от друга не зависящие (в том смысле, что результат не зависит от порядка их исполнения). Но в том конкретном месте конкретной программы, где они оказались рядом, из-за загруженности конвейера предшествующими командами, последовательность «X; Y;» будет исполнена медленнее, чем «Y; X;». Сможет человек это учесть?
(Причём в каком-то другом месте более быстрым окажется применение «X; Y;».)
В итоге и решение человека, и решение компилятора будут уступать А, но компиляторное окажется лучше человеческого.
(Битву за шахматы человек уже проиграл.)
А еще на современных процессорах многие алгоритмы упираются в производительность памяти, и тогда взаимное расположение команд уходит на второй план, потому что процессор всё равно тратит такты в ожидании данных.
Выполнение команд процессором намного проще шахмат, поэтому всегда будут люди, которые будут писать ассемблерный код лучше компиляторов. Ведь процессоры создают тоже люди, а уж создание процессора значительно более сложная задача, чем написание под него кода.
Алгоритм в любом случае создаёт человек. На долю творчества компилятора остаётся только оптимальное распихивание по регистрам (и памяти) результатов промежуточных вычислений. И с некоторых пор — выбор порядка выполнения некоторых операций.
Да. Компиляторы же стараются делать кроссплатформенными (как по части операционок, так и по части архитектур процессоров), и поэтому они не умеют выжимать максимум из каждой конкретной архитектуры. Но когда производитель процессоров делает компилятор, заточенный под конкретно его процессоры, то результат бывает куда лучше.
В том-то и дело, что в подобных случаях человек пишет по наитию, а специализированный на конкретном процессоре компилятор держит в себе информацию о внутренних подробностях исполнения команд процессором и может подобрать действительно наилучшую их последовательность, чтобы минимизировать ожидание. (В конце-концов, сами команды ведь тоже вычитываются из памяти.)
Оптимизирующий компилятор, как и в шахматах, берёт «грубой силой» — он в процессе работы способен оперировать гораздо большим объёмом информации и осуществлять полный перебор вариантов.
Многие процессоры сейчас чуть ли не студенты собирают из готовых библиотечных модулей как из блоков конструктора «Лего». И даже создание новых архитектур без использования типовых библиотек не обходится.
А с другой стороны, для VLIW-процессоров («Эльбрус» и др.) писать эффективные программы на ассемблере никто даже не пытается — настолько это дохлый номер.
Хороший прирост производительности можно получить, если выполнять операции параллельно используя MMX, SSE, SSE2, SSE3 и т.д. И как мне объяснить компилятору, что вот тут можно так сделать? Например, я решал задачу поиска пересечений линии с объектом, там надо выполнять одинаковые операции с разными данными, компилятор сам этого понять не смог, хоть и флаг использования SSE был включен.
А еще в Си прекрасный пример — это умножение. На интеле результат умножения имеет удвоенную разрядность, но Си это категорически не поддерживает. В результате приходится кастить аргументы к более широкому типу, после чего производить умножение. И даже вот тут не всякий компилятор понимает, что из 4-х команд умножения надо оставить лишь одну.
Да, не для любой системы команд человеку просто писать ассемблерный код. Но это не значит, что человек вообще не сможет написать лучше компилятора, это лишь означает, что всё меньшее число людей успешно с этим справятся. Но тот же x86/64 или AVR очень просты с точки зрения команд, поэтому в большинстве задач под них писать эффективный код относительно несложно.
Даже древние версии TurboPascal умели передавать параметры в функции через регистры. А мой любимый компилятор тех же времён позволял вручную для каждого параметра указывать, в какой именно регистр его засовывать.
А вот это и есть тот недостаток многоплатформенных компиляторов, который я упоминал. Алгоритмы оптимизации у таких компиляторов более-менее общие для всех поддерживаемых платформ, поэтому использование всяких уникальных особенностей идёт по принципу «как шмогла». Но, например, ISPC, заточенный сугубо на Intel, обещает кратный прирост производительности на таких задачах.
С тех пор, как в Интеловских процессорах появилось опережающее исполнение, простота команд стала обманчивой. Выше я это описывал. Человек реально не в состоянии учитывать особенности прохождения последовательности команд по конвейеру.
Да. Если на весь мир какая-то пара сотен человек знакома с внутренней кухней конвейера и может писать программы с учётом её, то это то же самое, что сказать: «Никто не может».
А если есть компилятор, который это автоматом учитывает, то круг успешных программистов расширяется в тысячи раз.
Опять же, какой памяти? Вы снова про виртуальные методы? Ну, так не делайте, они не всегда нужны.
Можно использовать __fastcall и С++ тоже будет передавать через регистры. Только регистров в х86 мало.
Опережающее исполнение появилось, емнип, еще во времена вторых пентиумов. Но только примерно в 2013-2015 годах я еще вполне успешно писал для х86 программы на асме, которые работали в полтора раза быстрее компилятора (MSVS).
А без них большинство «гениальных идей» ООП становится невозможным реализовать, и остаётся, по сути, один только изменённый синтаксис исходников.
В терминах того языка, на котором я предпочитаю писать, объект представляет из себя запись (RECORD), полями которой являются все его свойства, указатели на виртуальные методы и всякая разная служебная информация компилятора.
Каждый раз, когда порождается экземпляр класса, в памяти размещается вся эта запись, даже если реально в программе от всего «богатого внутреннего мира» объекта требуется только один метод, не имеющий параметров и не доступающийся к прочим свойствам объекта. А никакого иного способа вызвать данную «обычную функцию, имеющую постоянный адрес в памяти» у меня нет.
Да. Но я же написал это в связи с:
— чтобы напомнить, что использование регистров для передачи параметров в функции не является чем-то уникальным, присущим только работе с объектами.
Ничего удивительного. Я уже писал, что для выбора наилучшей последовательности машинных команд компилятор должен иметь информацию об особенностях исполнения каждой команды внутри процессора. Такой компилятор могут сделать только люди, хорошо знакомые с «внутренней кухней» процессора, и это будет компилятор, заточенный именно под этот процессор. Инженеры Intel способны на такое. Отдельные энтузиасты, глубоко зарывшиеся в документацию по процессору, тоже. Но создатели MSVC??? У них несколько другой вектор приложения усилий — не генерация максимально эффективного кода, а «громадьё библиотек».
Ничего подобного. ООП — это, прежде всего, инкапсуляция, когда объекты представляют собой «черные ящики». Для такого виртуальные методы нужны далеко не везде.
Если для вызова метода не нужен доступ к свойствам объекта, такой метод следует делать статическим. И если такого разработчики библиотеки по какой-то причине не сделали, это значит всего-лишь, что дураки они, а не ООП в целом.
Есть. Если это ваш код, просто перепишите, чтобы метод был статическим. Если это библиотечный код, посмотрите исходники, убедитесь, что метод реально не нуждается в данных. Затем просто вызовите его с нулевым указателем. Делов-то.
Компилятор можно настроить под себя, под проект и под его цели. Моя мысль была в том, что если компилятор не настраивать и перейти от f(x) к x.f(), то код станет даже быстрее, так что ООП само по себе еще совсем не означает снижение скорости.
Ну и кто будет пользоваться этим компилятором? Сейчас миллионы проектов собираются «универсальным» gcc, которому такая оптимизация и не снилась, поэтому ассемблерный код я сравниваю именно с ним.
Да, конкретно в этом случае сначала хотел написать, но потом подумал: «Всё равно ж удалю, когда перегруженный текст сокращать буду».
Это разве что для потомков С, где вся программа с точки зрения компилятора является одним сплошным текстом, собираемым из отдельных файлов с помощью препроцессорного #include. Но есть же ж куча других языков, в которых объектов нет и близко, а инкапсуляция — вот она, в полный рост. Чтобы далеко не ходить — тот же TurboPascal с его Unit-ами.
Не во всех языках есть такая концепция. В TCL, например, нет.
Но сам пример был выбран таким просто ради его максимального упрощения.
Давайте возьмём чуть более сложный и заглянем встроенным в браузер отладчиком в потроха любой веб-странички. Там мы быстро обнаружим, что у любого элемента странички есть сотни свойств и методов, не имеющих для данного объекта никакого смысла. Особенно это касается его CSS-свойств. Например, у любой картинки обязательно имеется несколько десятков свойств, имеющих смысл только для текста. Но память эти поля жрут.
А почему так? Потому что ООП с его наследованием. А при наследовании потомок получает от предка всё, что у того было. Потомку можно ещё добавить то, чего у предка не было, но нельзя при наследовании взять только часть имеющегося и отказаться от того, что заведомо не нужно.
Как его вызвать, если в языке даже нет понятия «указатель» (адрес переменной или функции)?
Вы же хотели эффективное использование MMX/SSEx/… Значит, можете предпочесть именно тот компилятор, который это обеспечивает.
А кому-то может быть нужно выжимать максимум скорости из обычных команд.
Вон, тот же Intel компилятор не только с C делает, но и с Fortran. Значит, людЯм надо.
(И я не удивлюсь, если где-то там внутри себя они для своих нужд и PL/M (не путать с PL/1!) до сих пор тянут.)
Нет. ООП предоставляет механизм наследования, но не заставляет вас его использовать. Если конкретно в js было решено унаследовать какой-то объект от какого-то, в этом виновато не ООП и наследование, а разработчики, которые так решили. Не нужны вам часть свойств базового класса — разбейте базовый на два, унаследовав один от другого. А теперь наследуйте свой класс от первого и он не получит «лишние» свойства второго. Как видите, любой вопрос в программировании решаем.
Когда мне начинают говорить про скорость и всякие оверхеды, единственные языки, которые я представляю — это С и С++. Остальные языки не про быстродействие в первую очередь, а про что-то еще — memory safety и т.п. Компиляторы в них тоже бывают неплохими (тот же Го неплохо оптимизирует), но у них на первое место поставлены другие цели. И это не всегда плохо — к примеру, на джаве пишется куча бэкендов, где 99% времени выполнения, в конечном счете, потратится на запросы в БД. Так какая разница, выполнится оставшийся 1% медленно или быстро, всё равно это практически никак не скажется на системе в целом. А вот писать безопасный код на джаве явно проще. Да и юнит-тесты по-настоящему раскрываются только с DI.
то в file2.h доступно всё то, что определено в file1.h
Если же «пустить в зачёт» тот факт, что содержимое комплектного file1.с извне таки недоступно, то это обесценит утверждение:
потому что file1.с — точно такой же «чёрный ящик» без всякого ООП.
И ООП тоже. Потому что без ООП в используемой чужой библиотеке будут переменные и функции, и использовать в своём коде можно только те из них, которые нужны.
А при ООП в чужой библиотеке будет класс, в который помещены все эти переменные и функции, и импортировать их выборочно возможности нет никакой.
Если же тот огромный класс из примера раздробить на кучу мелких, то потом, когда понадобится добавить что-то всем или многим из них (а наследуют ведь ради добавления), то проделать это придётся для каждого из мелких классов. (Да, есть двадцать мелких классов, в которые нужно добавить один и тот же метод, значит его двадцать раз и придётся добавить).
Поэтому авторам проще «так не делать», а держать всё в одном монстре.
А при классическом программировании и в самом деле достаточно будет добавить только одну функцию. Причём причина такой разницы — всего лишь синтаксис исходников.
А как в C++ сделать то, что Вы написали:
У меня такое получается только для метода объекта. Но целью-то было вызвать (статический) метод класса, не создавая объекта. А для класса у меня получить адрес метода не выходит, компилятор ругается. И на попытку вызвать его как MyClass.a() тоже ругается.
Может тогда сразу надо и от компьютеров отказаться? Глупо обвинять инструмент в плохом результате.
Переменные и функции всё так же можно использовать отдельно, потому что в классе — методы и свойства. Выборочный импорт методов и свойств — бред, т.к. импортированный методы может использовать то свойство, которое вы импортировать забыли.
Опять какая-то фигня. Если у этих 20 мелких классов нет общего предка, добавьте этот предок, и добавьте его в родителей 20 классов.
И снова ерунда. Какой тип параметра будет принимать эта функция, если у вас есть 20 независимых мелких структур?
Ничего личного, но я смотрю на ваши сообщения и понимаю, что у вас достаточно много пробелов в знаниях в программировании (по крайней мере, в С/С++). Отсюда и ваш негатив в сторону ООП, потому что фактически f(x) и x.f() даже после компиляции будет практически одним и тем же. Вы или явно передаете параметр, или неявно передаете его как this.
Статический метод вызывает без создания экземпляра штатно: Class::Method().
Обычный метод можно вызвать так:
Но это если только вы точно уверены, что методу не нужны свойства класса и другие свойствозависимые методы.
Пример может показаться надуманным и редковстречающимся, но реальность даже печальнее, чем то, что в нём предложено. Мне не раз приходилось писать на C для Windows с использованием одного только Windows SDK. Это одна библиотека, в которой, по идее, всё должно быть согласовано. Но стоит только начать, и поехало:
— «Тип А неизвестен»
Находим .h, в котором есть нужное определение, подключаем через #include.
— «Тип B неизвестен»
Находим .h, в котором есть нужное определение, подключаем через #include.
— «Тип С неизвестен»
Находим .h, в котором есть нужное определение, подключаем через #include.
— «Повторное определение типа А»
Всё, приплыли. Убираешь любой из #include — возвращается ошибка, что что-то не определено. Все #include присутствуют — «Повторное определение...»
Полдня мучаешься, пытаясь найти тот волшебный h-файл, подключение которого позволит обойтись без одного из «нехороших» #include — ничего не выходит. В конце-концов нервы не выдерживают, и просто копируешь нужные фрагменты в свой самодельный .h. Но эти фрагменты немедленно тянут за собой что-то ещё, и ещё, и ещё…
В результате у меня уже практически свой собственный вариант Windows SDK образовался. И ещё вариант его же, но уже на нормальном языке программирования, в котором определения в заголовочных файлах действительно изолированы друг от друга и поэтому подобных проблем в принципе быть не может.
Поэтому я и сказал, что инкапсуляция вполне возможна без ООП.
И теперь хочется спросить: Вам лично чем ООП в C++ помогает? Все виденные примеры, где от него хоть какой-то толк имеется, касались довольно узкого круга задач, с которым не очень много людей сталкивается. А в тех реальных чужих исходниках, с которыми мне иметь дело приходилось, пользы от него не было вообще, одна только головная боль от переусложнённого текста.
А использовать инструмент не по назначению?
Но это же просто другое название для того же самого. Однако функцию можно задать одну и засовывать в неё всякое разное, а новый метод разным классам придётся прописывать индивидуально. И хорошо ещё, что в C++ саму функцию можно один раз задать и N раз прописать, а не N копий тела функции вставлять. (Да и то не факт. Вдруг классы в разных файлах описаны?..)
Ага. Огромный класс раздробили на 100 простых, происходящих от одного предка. Потом 20 из них понадобилось расширить. Задали для них нового (промежуточного) предка, в который и добавили новый метод.
А чуть позже понадобилось расширить ещё 20 классов — десять из этих двадцати и ещё десять из оставшихся девяноста…
Наверное, найдётся способ выкрутиться с помощью ещё какого-то нового класса. Но каждый раз, когда понадобится расширяться, придётся добавлять новые промежуточные классы, связь между которыми быстро станет невероятно запутанной. С печальными результатами мне сталкиваться приходилось. Не помогало даже заботливо построенное авторами графическое дерево связей между классами — в этом мелком кружеве линий отследить что-либо было совершенно невозможно.
Зависит от того, за что боремся — за память или за скорость. И от языка программирования. Поскольку здесь я стараюсь оперировать названиями известных языков, то в Pascal (и TurboPascal) это, скорее всего, будет «запись с вариантами». А может и просто записью (в С это struct) обойтись удастся. Но это уже от конкретной ситуации зависит.
С C у меня проблем нет, а вот с C++ отношения — да, очень напряжённые, хотя он и был создан, когда я уже весьма активно программировал, и вся его эволюция происходила на моих глазах. Просто, глядя на эту его эволюцию, я достаточно быстро пришёл к двум выводам:
1. С++ — воняющее кладбище чьих-то гениальных идей.
2. От языков, новые версии которых появляются чуть ли не каждый год, лучше держаться подальше.
Наблюдение за некоторыми другими языками пункт 2 полностью подтвердило.
Кроме случаев, когда x не нужен (а именно об этом случае и был вопрос). Для вызова функции можно написать f(), а для вызова метода придётся поизвращаться указанным Вами способом.
Кстати, на Ваш пример компилятор ругается:
И, пользуясь случаем, спрошу: что могло быть причиной того, что во многих местах одной из моих C++-ных программ прекрасно работали примерно такие последовательности:
и они же не работали, будучи объединены в один оператор:
Программа тихо валилась, хотя и памяти, и стека было более чем достаточно.
Написал именно так достаточно много приложений, ни разу не столкнулся с подобным. Да есть там WIN32_LEAN_AND_MEAN, если его отключить, могут быть конфликты, но они решаются весьма легко.
Проблема в том, что Win SDK обновляется.
Нет. Без ООП у вас будет полностью открытая структура и функции. Никаких private переменных. Конечно, можно сделать две структуры — публичную и личную, вторую определить уже в С файле, но с ООП это гораздо проще.
Прежде всего, виртуальными функциями. Например, я описываю интерфейс, добавляю реализацию, код работает. А завтра я добавляю вторую реализацию, и без какого-либо труда подключаю её в свой проект. Более того, я еще пользователю могу выбор дать, какую реализацию использовать. Конечно, я мог бы и на plain-c реализовать такое, можно же адрес функции в структуру загнать, но на ООП это в разы удобней.
А это уже не проблема инструмента.
В С/С++ — нет. У вас есть функция, она принимает строго определенный тип. С другим (если он не потомок первого) работать не будет. А если потомок, то это ведь то же самое наследование.
Мне кажется, наигранный сценарий. Но, в любом случае, это возможно. А еще есть множественное наследование, и хоть есть много рекомендаций его не использовать, иногда оно может решить как раз вашу задачу более элегантно.
Не сможет одна функция работать с разными данными. Чисто физически, на уровне машинного кода. Единственное исключение — шаблоны. Но там для каждого типа генерируется своя функция.
С++ — великолепный язык, сочетающий в себе простоту и близость к процессору языка С с высокоуровневыми конструкциями типа шаблонов и ООП. Правда сейчас он развивается несколько не в ту сторону, но сейчас времена другие — на первое место начинает выходить memory safety, а не быстродействие.
Если х не нужен, функция должна быть статической! Если это не так, виноват автор кода, но не язык.
Да, ошибся, для каста static_cast нужен:
typedef LONG NTSTATUS;
а в четвёртой вставлена куча типов и констант из iphlpapi.h и udpmib.h, и об этом прямо написано в комментариях к этим вставкам. Причём сам файл iphlpapi.h тоже подключён — вместе с ещё шестью другими файлами SDK. Очевидно, что разблокировка тех #ifdef, в которые в iphlpapi.h засунуты эти определения, вела к упомянутым выше конфликтам.
Ага, когда выходит очередная версия Windows. Но при этом туда всего лишь добавляется что-то новое, пользоваться которым категорически не следует, если хочешь, чтобы твоя программа работала и под предыдущими версиями Windows тоже.
Концепцию приватных членов придумал не автор C++. И даже не создатели самого первого объектно-ориентированного языка. Они позаимствовали её из уже существовавших до того обычных функциональных языков. (И даже сам синтаксис для доступа к членам класса «через точку» был целиком содран с тех предшественников. Так что это всё идеи и технологии ещё 60-х годов.)
Оп-па! Я говорил, что бывают задачи, для которых применение ООП действительно оправдано. Но в этих ситуациях неизбежно возникает необходимость в полиморфизме и виртуальных функциях — тех самых, которые Вам так не нравились. И мы тут диспутируем именно о конструкциях без них.
Совершенно верно — это наследование. И вот мы уже имеем, что из трёх базовых принципов ООП (инкапсуляция, наследование, полиморфизм) два имеются и без ООП — «запростотак». (Полиморфизм тоже имеется, вы это сами понимаете: «можно же адрес функции в структуру загнать, но на ООП это в разы удобней» — и с первой частью этого я полностью согласен. А по второй несогласие могу выразить разве что насчёт «в разы». У языков-предшественников вполне себе существовал тип «указатель на функцию», и им обыденно пользовались. Это у нынешних программистов подобных навыков нет.)
Идея объектов выросла из идеи структур (struct, record) и была всего лишь мелким шагом вперёд, добавлявшим чуток удобства при написании исходных текстов — доступ к полям классов-потомков оставался «одноэтажным», а не «многоэтажным» как у структур-потомков.
Но параллельно и в некоторых обычных языках реализовали сохранение одноэтажности, введя понятие расширения типа, оформляемого в духе:
Вовсе нет. Исходным примером же было представление веб-странички в виде DOM-дерева, а там подобное частичное совпадение свойств и методов у разных подмножеств элементов — куда ни плюнь.
Да, это и есть способ решить ту задачу, породив чёртову уйму промежуточных классов, в которой потом хрен разберёшься. Создатели браузеров явно решили, что их супер-мега-гипер-класс — меньшее зло.
Напоминаю условия поставленной Вами задачи: «Есть класс, от него породили потомка, добавившего к родительским поля новые. Методы родителя прекрасно работают с экземплярами потомка. Как сделать то же без ООП?»
Если компилятор очень умный и способен понять, что ParentType является началом ChildType, то он и запись = Func(x); может позволить. Или если я готов несколько пожертвовать строгостью проверки типа параметра.
П-р-о-с-т-о-т-у? Боже мой! Да он настолько перегружен всякой хренью, что является одним из ярчайших примеров того, как нельзя делать языки.
Вы можете назвать хоть один язык, который сложнее, чем C++?
Да-да-да. И вызываться как class::f(), а не как x.f(). А человек для сотен методов разных классов должен постоянно помнить, какой как вызывать. Всё же очень просто.
Среди этих методов не было ни одного моего. Все они были из одной и той же библиотеки (Qt). Править её исходники и перекомпилировать у меня сейчас возможности нет (хотя в прошлом я это несколько раз делал).
Но я при описании тогдашней картины несколько неаккуратно выразился — программа не «тихо валилась», а просто молча завершалась. При этом от неё самой никакого сообщения об аварии не было. И от Windows никаких сообщений не было. А если запускал под отладчиком, то и отладчик писал только, что программа нормально завершилась.
Думаю, что если бы было преждевременное уничтожение каких-то объектов, то программа или упала бы по ошибке доступа к памяти, или продолжила бы нормально работать (ведь при уничтожении объекта, как и при удалении файла, данные какое-то время продолжают существовать на прежнем месте).
Я подумал, что, может быть, дело в моём недостаточном знании C++, и не всякий объект пригоден к использованию в цепочке.
Я никогда не говорил, что мне не нравятся виртуальные функции, я говорил, что они добавляют лишнее чтение из памяти. Что именно выбрать — решает программист.
Что касается примера без них — пожалуйста. У вас есть объект, вы делаете какое-то его свойство private, а для работы с ним извне добавляете getter/setter. Теперь любой, кто пользуется вашим объектом не может менять свойство напрямую, а должен вызывать getter/setter, в которых вы можете выполнить все нужные дополнительные операции по обновлению внутреннего состояния объекта. Без ООП вам пришлось бы лишь документировать необходимость обновления внутреннего состояния и надеяться, что разработчики прочитают и последуют вашим рекомендациям. То есть, ООП банально позволяет снизить количество багов в продукте.
Нет. Инкапсуляции нет. Вы не можете сделать часть свойств класса private, вы можете лишь попытаться скрыть часть определений внутри реализации (с-файла). Однако, вы не сможете далее наследоваться от этой реализации в других файлах. Полиморфизма тоже нет, т.к. использование адресов функций не есть полиморфизм, это костыль, помогающий его заменить. Также вы забыли четвертый базовый принцип — абстракцию, которой нет без ООП. Остается только наследование.
Так это и хорошо, манипуляция с указателями — потенциально опасная операция и очень хорошо, если компилятор берет эту задачу на себя. Но, впрочем, никто вас не ограничивает, если хотите, можете использовать указатель на функцию и сейчас, и есть даже специальный объект std::function<>, который призван вам в этом сильно помочь.
Наверное, оно так и есть. Ведь на plain-c вы бы просто не смогли написать приложение уровня браузера — погрязли бы в багах. А если предположить, что средний размер картинки в памяти составляет, скажем, 25 КБ, тратить лишние 200 байт на ненужные свойства — не так уж и заметно.
Так вы не вызываете функцию с другим типом, вы у другого типа получается базовый и вызываете функцию с ним. То есть, исходной вашей формулировке «засовывать в неё всякое разное» это, ну, никак не соответствует. По аналогии, вы можете у объекта сделать метод, который возвращает другой объект и вызывать нужный метод у другого объекта. Так что связь между методами и функциями, которые принимают структуру 1-к-1.
Простота — это была про Си. С++ непростой, но как я сказал — он сочетает простоту Си с наворотами С++. Но как именно использовать эти навороты — решаете вы.
Не занимайтесь софизмом, пожалуйста. Во-первых, если у вас есть указатель на экземпляр, вам всё равно, вы можете и статический метод вызвать как x.f(). А если экземпляра нет, вам надо будет смотреть заголовок, чтобы понять, как определен метод. Или использовать современную IDE, которая подскажет сама. Но ведь в plain-с всё так же — часть методов будут принимать указатель на структуру, часть нет, и вы должны это помнить.
Возможно, там есть верхнеуровневый обработчик исключений, который отлавливал исключение и тихо выходил. Возможно, происходило что-то еще. Если это не ваш код, можно было бы попробовать обернуть все объекты в свои классы, где сделать логирование при создании и уничтожении. Да, муторно, но, скорее всего, даст ответ.Вообще, время жизни промежуточных объектов должно расширяться до тех пор, пока операция не будет выполнена, поэтому тут надо копать глубже — возможно, ошибка в компиляторе.
В принципе, проект и публиковался именно для демонстрации возможности простейшим контроллером и минимальным кодом обмениваться с индикатором и измерителем температуры.
Следующий шаг будет — сделать паяльную станцию с таким индикатором на таком же контроллере.
Попытаемся в килобайт памяти впихнуть код с приемлемым функционалом паяльной станции.
Вы сомневаетесь, что без ПИД можно поддерживать температуру с достаточной точностью?
В килобайт памяти вряд ли получится ещё и ПИД встроить.
Нет, формально там конечно интеграл и производная, но покуда у вас микроконтроллер тактируется, то их вы будете считать из дискретного ряда значений. Ну а интеграл – суть сумма всех, а производная – разность двух последних.
Вот практическая реализация ПИДа и сведётся к арифметике на пальцах.
У AlexGyver был наглядный урок/статья про пид регулятор – там можно и теории покурить чтобы свой сделать и просто код своровать, скорее всего есть библиотека, он любит велосипеды писать.
Не думаю, что оставшейся памяти хватит для реализации ПИД.
Да и смысла сильного не вижу.
В чём в паяльной станции преимущество ПИД?
Здесь я с Вами соглашусь, что для паяльника гонка за точностью не имеет практического смысла.
Смысл ПИДа еще и в том, чтобы уйти от автоколебаний, когда система за счет инерционности проскакивает установленное значение — датчик читает текущее значение и командует на возврат — возврат снова с проскоком из-за различных причин (та же самая инерция, например) — команда на обратный возврат в точку — ну и понеслась дерготня. Особенно замечательно будет, если после тяжелого полигона бросить паяльник на подставку — он еще какое то время будет качаться туда сюда туда сюда ) простой способ подавления через введение гистерезиса — ну да, наверное, проблему (отчасти) решит… «Жили же до этого как-то без этого» ©
но тогда другой вопрос от нашего читателя Олега Груненкова встает вертикально ))) то есть мы «городили городили да не выгородили»: зачем МК+вся электроника +..+..+..., если в конце концов мы вынуждены вернуться к введению гистерезиса как к самому простому, давно известному не идеальному способу подавления АК как в обычном начального уровня пропорциональном регуляторе с обратной связью??? А в Вашем случае гистерезис выглядит единственным действенным способом, в противном случае Вы сами сказали, что немедленно упираетесь в потолок по объему кода…
Красоту проекта я оценил. Трудозатраты — Вы молодец. Лаконичность кода — отлично ))) знание матчасти, умение пользоваться паяльником+программирование — супер.
Практическая значимость — ? Хотел бы повторить — Х. Рекомендовал бы кому-то к повторению — Х.
«Демонстратор возможностей» ©
Просто мне нужен был свой термометр. Решил сделать из того, что было под рукой.
Глянул поисковиком — не нашел подходящего варианта на ATTiny13 + TM1637.
Ну и решил добавить MAX и поупражняться со сжатием кода.
А, заодно, поделиться практическими решениями компактного кодирования для ATTiny13. Может кому полезно будет при освоении простых контроллеров.
А для паяльной станции, может, ATTiny85 возьмете? Там все же памяти побольше.
вот тут что-то было на тему mysku.club/blog/diy/103561.html
Тиньки я брал давно и меньше, чем по пол доллара.
Для простой паяльной станции на дисплее TM1637 тинек вполне хватает.
Для навороченной паяльной станции вполне хватит LGT8F328, которых тоже валяется жменя (тоже меньше, чем по доллару за штуку).
Ну и каких возможностей мне с ними не хватит?
Вот и я про то же — ну нельзя всё деньгами мерять.
Как измерить удовольствие, полученное от того, что получилось решить поставленную себе задачу. ))
Хобби оно же не для денег.
Это же вдвойне приятнее. ))
Про рейтинг это не ко мне — я довольно редко пишу здесь статьи. И чужие практически не комментирую.
Вроде и не сильно критично 10 градусов, а неприятно.
И таки да — очень приятно доверять показаниям ампервольтметра.
mysku.club/blog/diy/105881.html
mysku.club/blog/diy/105870.html
Может мне важнее удовольствие получить от того, что удалось впихнуть нужный функционал в такую малютку-контроллер. ))
Я вот про это Вам написал «время, потраченное на впихивание в этот килобайт».
Вы моё время и работу, которую я делаю для души, пытаетесь в деньги переводить. ))
А приводить Вам в качестве аргумента «работу для души» явно же бесполезно. ))
Вы в таких категориях, как я понял, мыслить не привыкли. ))
«Захотелось попробовать» — абсолютно достаточный аргумент, никакие иные не нужны.
Не просто захотелось. А с одной стороны возникла потребность в устройстве.
С другой был некий задел по комплектующим, что позволяло получить результат за недорого. И с третьей — действительно посчитал, что приятнее будет сделать своими руками прибор более компактный, удобный и с возможностями развития, чем покупной и параллельно подготовить компактный код для паяльной станции на ATTiny13…
Недавно тоже отвечал на подобное:
mysku.club/blog/diy/105562.html#comment4773963
Захотел — сделал, хочет — оправдывается, хозяин-барин ))
Я пытаюсь объяснить, что кроме финансовой мотивации, могут быть и другие аргументы:
— получить удовольствие от собственной работы,
— поделиться, возможно полезными, способами минимизации кода с любителями покопаться с тиньками
— заинтересовать кого-то возможностью создания на базе простого устройства собственных расширенных решений (высокотемпературного терморегулятора или контроллера превышения температуры, например).
Но далеко не всегда получается объяснить это людям, пересчитывающим моё свободное время на деньги. ))
У него, кстати, есть интересный проект паяльной станции на агдуинке.
Я для себя его немного подшаманил — переделал на LGT8F328, добавил возможность работать с С245 дополнительно к Т12 и русифицировал меню.
Пришлось правда свои шрифты русские делать. С русскими шрифтами U8g2lib.h — не хватает памяти.
Ну нету у меня тиньки 25. А десяток тинек 13 ещё завалялся. ))
Почему нельзя было сразу _delay_ms(100)? В чем была такая необходимость делать через цикл? Я понял, что в макрос _delay_ms нельзя подставить переменную, но у вас в коде вроде бы везде константы прописаны.
Для чего переменные kd и ks? Я увидел что они для вывода на экран, но для чего они в принципе, что вы из них иногда вычитаете сотни и десятки?
Тот код, что в статье, даёт при компиляции скетч в 362 байта. Если заменить функцию delay_msTK на макрос _delay_ms() во всех местах в программе, то объём скетча вырастает до 402 байт. Я думаю, что это происходит потому, что макросы вставляются в программу напрямую, а не используются как однажды написанная и многократно используемая функция.
С такой же целью используются для получения значений десятков и сотен счётчики kd и ks вместо кода типа
int ed = t % 10; // 3 (единицы)
int des = (t / 10) % 10; // 2 (десятки)
int sot = (t / 100) % 10; // 1 (сотни)
который даёт ещё больший прирост размера программы — до 452 байт.
Счётчики экономичнее, чем деление. Особенно для ATTiny13 и им подобных AVR с урезанным математическим функционалом.
Что не так?
А по умолчанию Arduino IDE и так компилирует код с флагом -Os (оптимизация по размеру).
Впрочем, Вы всё можете проверить сами — код программы в статье есть.
Они обе типа «К» и дают одинаковый результат.
Только в том, что от мультиметра, уже есть подходящие контакты.
Хотя Вы, наверное правы — стоит добавить в статью.
Вечером подправлю.
На плате капелькой припоя ножки 1 и 2 соединены. Вот фрагмент фото, на котором это хорошо видно.
Мне для кода паяльной станции на ATTiny13 важно было попробовать минимизировать код работы с TM1637, которая будет индикатором и обработчиком нажатий кнопок, а также управления пищалкой в схеме паяльной станции.
нет смысла пытаться сделать это в тини13. Никакого. Вообще. Ладно бы если вопрос был 20 лет назад то все равно можно было бы рассматривать tiny25-45-85 или mega48-88-168-328, как полнофунциональную замену если место закночится. Но тут нет. Тини13 ни на что не заменить без серьезного переписавания кода.
Практического смысла оптимизировать код для AVR в 2026 — нет. Это ничем не поможет при разработке для stm32 или каких-нибудь risc-v.
B вы не «продадите» это даже тут или вообще в любом OSHW сообществе. Просто потому что не у всех есть «запасы», а покупать авр сегодня — бессмысленно.
Я вот для электросамоката внуку делал на тиньке «плавный газ». Малюсенькая такая платка 2х2 см.
Вы серьёзно думаете, что это стоило делать не на тиньке, а на синей плате STM32 и потом попробовать это впихнуть в батарейный отсек самоката, где особо и места нет лишнего.
2х2см — я бы на сегодня взял есп32-с3 (если там подходит по напряжению и прочим факторам)
Обычно же в промке ставят второй датчик температуры прям у клемм подключения кабеля термопары и измеряют темературу холодного спая. Чтобы по ней компенсировать дрейф.
Тут такое есть?
Тем не менее, даже здесь, в комментариях к этой заметке раздаётся громкое «фу-у-у, купи мультиметр!».
И именно поэтому мультиметр при отсутствии термопары показывает комнатную температуру.
Да, диод нормально работает в довольно узких пределах, но и мультиметром никто не пользуется ни при -30, ни при +80.
При написании кода для своих решений без спец микросхем, можно просто принять примерно 20 радусов в качестве температуры холодного спая, если будете измерять в нормальном помещении.
Прикрутил термопару, запускаю в работу — показывает, что в комнате 28,5 градусов. А я сижу возле открытой двери на балкон, и за бортом сейчас +15.
Удивился, заменил штатную термопару на ту, которая шла в комплекте с мультиметром. Стало показывать 30 градусов.
Прикрутил опять первую — 30,5.
Ага, значит как минимум с термопарами всё более-менее в порядке.
Стал думать, что это всё может значить и как с погрешностью программно бороться (в микросхеме же никакой задаваемой пользователем коррекции не предусмотрено).
Пока думал и занимался другими делами, прошло минут 10, а программа всё это время работала, и смотрю — а показывает-то уже реалистичную температуру — 26,5.
Ту-то я и сообразил, что когда первую термопару к этому крохотному модулю прикручивал, микросхемка от руки нагрелась. Когда откручивал и прикручивал другую — нагрелась ещё больше. А потом полежала на столе, остыла…
Но ведь, по логике, при нагреве микросхемы выдаваемые ею показания должны или оставаться неизменными (если внутренняя коррекция есть), или уменьшаться по отношению к исходным (если коррекции нет). Почему же у меня они увеличились?
Результат аналогичный. Держу минуту палец на микросхеме MAX6675. Температура растёт с 25 до 32 градусов.
Отпускаю палец — температура плавно начинает снижаться до первоначальной.
То есть микросхема складывает свою температуру с рассчитанным значением на основе данных от термопары.
Что должно меня заставить использовать его в столь простом и дешевом устройстве?
Есть и защита от обрыва термопары, и защита от перегрева, и отключение через три минуты при установке ручки на подставку, и режим сна, и работа с двумя типами жал (Т12 и С245), и свето-звуковая индикация аварийных режимов, и турбо режим, и калибровка с шагом 5 градусов, и подстройка точности температуры подстроечным резистором, и изменение температуры кнопками с шагом 10 градусов.
ПИД нету, но и без него нормально куча проектов работает.
Гистерезиса в пару градусов вполне достаточно, чтобы не было качелей.
А чего ещё вам не хватает в функционале паяльной станции? ))
Удобный и бесплатный инструмент.
Ещё не выкладывали?
или ещё возитесь...?
А так TM-902C на Али/Озоне чуть больше 300р
Но я не в РФ.
А на Алике ниже 500 рублей со стоимостью доставки не вижу.
https://aliexpress.ru/item/1005010777196446.html
Это снова цена для РФ.
Вот Вам скрины на тот же товар в том же магазине, но с отправкой в Чехию.
Докупаете к нему Крону и получаете те же 600 рублей.
А что для разных стран мира цены разные — так оно всегда так было.
Плюс не забываем о милой привычке Aliexpress показывать не все из имеющихся предложений, из-за которой разные покупатели даже из одного города могут видеть существенно разные списки.
То есть, не исключено, что и для Чехии есть более дешёвые варианты.
Потому что я за справедливую оценку. Вы выше писали, что ничего меньше 500 рублей нет, но вот вам лот за 3.7 евро, что значительно меньше 500 рублей. Что касается бесплатной доставки — тут достаточно добавить еще что-то за 5 евро.
А батарейка — её и на озоне нет в комплекте.
Во-вторых, я Вам привёл пример именно вашего продавца с именно вашим товаром с приведённого Вам скрина. И там цена другая, как Вы можете видеть.
Если для Вас новость, что и цена товара и цена доставки для разных стран может быть разная, то я Вас поздравляю — Вы одогатили свои знания новым богатым опытом.
Можете сами указать другую страну и посмотреть, что выдаст Али по цене товара и цене доставки.
А то, что это был немецкий сайт, значения не имеет. Имеет значение в какую страну доставка.
Если вы перечитаете все мои комментарии, то не найдете в адрес вашего устройства ни одного слова осуждения или сравнения его цены с покупным. Я спорю только с двумя вашими другими утверждениями — что мультиметром нельзя нормально измерить температуру (можно), и что готовый термометр нельзя дешево купить на али (тоже можно).
На вашем скриншоте цена 3.7 евро и бесплатная доставка при заказе на 8.7 евро. Именно об этом я писал выше, 3.7 евро меньше 500 рублей, а корзину можно добить другим товаром на 5 евро для получения бесплатной доставки.
Немецкий сайт не может доставлять в Россию, как вам справедливо заметили выше.
Я не знаю, что Вы указывали как страну назначения на немецком сайте.
Но этот же товар от этого же продавца бесплатно в Чехию не доставляется, как я Вам и показал на скрине.
По мультиметру готов уточнить — нельзя точно измерить ДЕШЕВЫМ мультиметром. Под словом ТОЧНО, в данном случае я говорю о точности в 1 градус, котоую я без проблем получил с MAX.
И по поводу конструкции — сделано красиво, но зачем возится коли есть заводской TM902C который делает тоже самое? И что важно — его можно поверить/откалибровать в любой метрологической лаборатории и тогда его показаниям можно будет доверять.