Делаем из кнопок и светодиодов минипанельку управления. Кнопки 6X6X10MM 4PIN без фиксации.

- Цена: $0.99 за 50 штук
- Перейти в магазин
Как бы не было модно управлять устройствами с помощью современных интерфейсов (телефон, пульт, компьютер и т.п.), все-таки старые добрые кнопки зачастую удобнее, так как расположены в одном месте, как правило, рядом с тем устройством на которое требуется оказать воздействие. Стоят они недорого, поэтому если есть возможность, лучше обеспечить свою поделку (или доработанную чужую) местным интерфейсом управления. Именно про такой интерфейс и пойдет речь в обзоре. Под катом нехитрая поделка, arduino, ну и, собственно, немного про данную конкретную кнопку.
Посылка приехала за 3 недели, трек не отслеживался. Кнопки в пупырчатом пакете, проложены картонкой, ножки не погнулись. В пакетике их было 48 штук (спор открывать не стал :)). Собственно, предмет обзора:



Приведу чертеж такой кнопки:
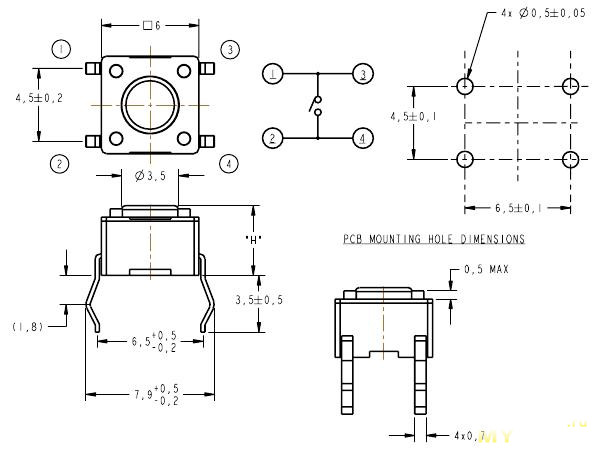
H — в данном случае, 10 мм, но существуют варианты как длинней так и короче, в зависимости от потребностей.
На фото данного продавца представлен целый набор цветов и размеров:

На следующей картинке представлен весь спектр выпускаемых китайской промышленностью кнопок такого типа, отличаются они только высотой штырька:

В общем, выбор неплохой. Есть также угловые версии, типа таких:

Размеры кнопки совпадают с чертежом:


Кнопка нажимается мягко, я их использовал уже в своих поделках и нареканий к их работе не имею.
Продавец пишет про медь, поверим магнитом:

Следует сказать, что контакты равнодушны к магниту, а вот верхняя фиксирующая пластина магнитится, собственно, все хорошо с этим.
Зачастую, в качестве самой кнопки используют иную деталь, которая нажимает непосредственно на данную кнопку, это позволяет создавать красивые кнопки устройств. Помимо этого, на кнопки можно купить разноцветные колпачки, например такие:

В общем, разнообразие ограничивается только фантазией.
Если вы заказываете платы в Китае, и ваш производитель плат допускает панелизацию, то вполне можно вставить в свою плату маленький кусочек с полезным функционалом. У меня была такая ситуация, и я решил не выкидывать оплаченный текстолит, а использовать его для простых целей: разместил на нем 3 кнопки с подтягивающими резисторами и 2 светодиода с ограничительными резисторами. Резисторы использовал smd1206 (подтягивающие кнопки на 10КОм, токоограничительные для светодиодов на 680 Ом), а светодиоды стандартные 5 мм. рисовать схему, думаю, в данном случае ненужно. Получилась нехитрая платка:


Скачать файлик с платой в формате Sprint Layout можно по данной ссылке.
Конфигурация, в моем случае, определялась свободным кусочком платы и возможным применением. Вы же можете расположить так как удобно вам. С одной стороны платы я решил расположить кнопки и светодиоды, с другой все остальное. Плата имеет отверстия по краям, пригодные для крепления ее к корпусу. Припаиваем детали:



Совсем не обязательно светодиоды припаивать вплотную к плате, можно подобрать длину выводов подходящую к вашему корпусу. Плата в полной комплектации подключается семью проводами: 3 на кнопки, 2 на светодиоды и питание (для подтяжки кнопок) с землей.
В качестве тестового устройства используем Arduino Nano, подключив ее проводками:

Чтобы было не скучно, напишем простую программку (но имеющую амбиции на правильную работу с кнопками). Наша программа обрабатывает все три кнопки и переключает оба светодиода. Первая кнопка включает и выключает красный светодиод, вторая зеленый, а третья инвертирует состояния обоих светодиодов:
Я постарался и прокомментировал фактически все строчки в программе, так что ее можно использовать как заготовку для своих поделок. Естественно, там где включается светодиод можно делать и иные действия, например управлять реле из этого обзора.
Видео, иллюстрирующее работу нашей панельки с данным кодом:
С такой платкой удобно отлаживать свои поделки (тут и индикация и подтянутые кнопки(датчики)). В случае применения в реальном устройстве совсем не обязательно припаивать все детали, например, можно оставить два светодиода и одну кнопку.
Кнопки оказались рабочими и полезными, к покупке рекомендую.
Спасибо всем, кто дочитал этот обзор до конца, надеюсь кому-то данная информация окажется полезной.
Посылка приехала за 3 недели, трек не отслеживался. Кнопки в пупырчатом пакете, проложены картонкой, ножки не погнулись. В пакетике их было 48 штук (спор открывать не стал :)). Собственно, предмет обзора:
Приведу чертеж такой кнопки:
H — в данном случае, 10 мм, но существуют варианты как длинней так и короче, в зависимости от потребностей.
На фото данного продавца представлен целый набор цветов и размеров:
На следующей картинке представлен весь спектр выпускаемых китайской промышленностью кнопок такого типа, отличаются они только высотой штырька:
В общем, выбор неплохой. Есть также угловые версии, типа таких:
Размеры кнопки совпадают с чертежом:
Кнопка нажимается мягко, я их использовал уже в своих поделках и нареканий к их работе не имею.
Продавец пишет про медь, поверим магнитом:
Следует сказать, что контакты равнодушны к магниту, а вот верхняя фиксирующая пластина магнитится, собственно, все хорошо с этим.
Зачастую, в качестве самой кнопки используют иную деталь, которая нажимает непосредственно на данную кнопку, это позволяет создавать красивые кнопки устройств. Помимо этого, на кнопки можно купить разноцветные колпачки, например такие:
В общем, разнообразие ограничивается только фантазией.
Если вы заказываете платы в Китае, и ваш производитель плат допускает панелизацию, то вполне можно вставить в свою плату маленький кусочек с полезным функционалом. У меня была такая ситуация, и я решил не выкидывать оплаченный текстолит, а использовать его для простых целей: разместил на нем 3 кнопки с подтягивающими резисторами и 2 светодиода с ограничительными резисторами. Резисторы использовал smd1206 (подтягивающие кнопки на 10КОм, токоограничительные для светодиодов на 680 Ом), а светодиоды стандартные 5 мм. рисовать схему, думаю, в данном случае ненужно. Получилась нехитрая платка:
Скачать файлик с платой в формате Sprint Layout можно по данной ссылке.
Конфигурация, в моем случае, определялась свободным кусочком платы и возможным применением. Вы же можете расположить так как удобно вам. С одной стороны платы я решил расположить кнопки и светодиоды, с другой все остальное. Плата имеет отверстия по краям, пригодные для крепления ее к корпусу. Припаиваем детали:
Совсем не обязательно светодиоды припаивать вплотную к плате, можно подобрать длину выводов подходящую к вашему корпусу. Плата в полной комплектации подключается семью проводами: 3 на кнопки, 2 на светодиоды и питание (для подтяжки кнопок) с землей.
В качестве тестового устройства используем Arduino Nano, подключив ее проводками:
Чтобы было не скучно, напишем простую программку (но имеющую амбиции на правильную работу с кнопками). Наша программа обрабатывает все три кнопки и переключает оба светодиода. Первая кнопка включает и выключает красный светодиод, вторая зеленый, а третья инвертирует состояния обоих светодиодов:
// функция вычисления количества элементов в массиве любого типа
template<typename T, size_t n> inline size_t arraySize(const T (&arr)[n]) {
return n;
}
uint8_t led1_pin = 5; // красный
uint8_t led2_pin = 6; // зеленый
// Текущее состояние светодиода 1
bool led1_on = false;
// Текущее состояние светодиода 2
bool led2_on = false;
// опишем кнопку
typedef struct {
uint8_t pin; // пин
bool state; // текущее состояние (1 по умолчанию, так как подтяжка к питанию)
bool changed; // необработанный факт смены
unsigned long start_change; // время начала смены состояния
} BtType;
// массив из 3-х кнопок
BtType BT[] = {
{2, true, false, 0}, // 1-я кнопка
{3, true, false, 0}, // 2-я кнопка
{4, true, false, 0}, // 3-я кнопка
};
// количество кнопок
uint8_t NumberBT = 0;
// Защита от дребезга, мс
unsigned long DEBOUNCE_TIME = 50;
// Текущее время
unsigned long CurrentTime = 0;
void setup() {
// Светодиоды - это выходы
pinMode(led1_pin, OUTPUT);
pinMode(led2_pin, OUTPUT);
// Вначале не светим
digitalWrite(led1_pin, LOW);
digitalWrite(led2_pin, LOW);
// текущее количество кнопок
NumberBT = arraySize(BT);
// Кнопки - это входы
for (uint8_t i = 0; i < NumberBT; i++) {
pinMode(BT[i].pin, INPUT);
}
}
// контроль кнопки
void button_control(uint8_t i) {
// если состояние отличается от текущего
if (BT[i].state != digitalRead(BT[i].pin)) {
// если не начат отсчет времени защиты от дребезга - начинаем
if (BT[i].start_change == 0) BT[i].start_change = CurrentTime;
// если это не дребезг, меняем состояние
if (CurrentTime - BT[i].start_change > DEBOUNCE_TIME) {
BT[i].state = !BT[i].state;
BT[i].start_change = 0;
BT[i].changed = true;
}
// это все-таки дребезг :)
} else {
BT[i].start_change = 0;
}
}
// основной цикл
void loop() {
// Устанавливаем текущее время
CurrentTime = millis();
// Проверяем все кнопки
for (uint8_t i = 0; i < NumberBT; i++) {
button_control(i);
// если текущая кнопка изменила состояние на нажатое
if (BT[i].changed && BT[i].state == false) {
// первая кнопка меняет красный светодиод
if (i == 0) {
led1_on = ! led1_on;
digitalWrite(led1_pin, led1_on);
// вторая кнопка меняет зеленый светодиод
} else if (i == 1) {
led2_on = ! led2_on;
digitalWrite(led2_pin, led2_on);
// третья кнопка инвертирует оба
} else if (i == 2) {
led2_on = ! led2_on;
digitalWrite(led2_pin, led2_on);
led1_on = ! led1_on;
digitalWrite(led1_pin, led1_on);
}
}
// отжатие кнопки мы не обрабатываем
BT[i].changed = false;
}
}
Я постарался и прокомментировал фактически все строчки в программе, так что ее можно использовать как заготовку для своих поделок. Естественно, там где включается светодиод можно делать и иные действия, например управлять реле из этого обзора.
Видео, иллюстрирующее работу нашей панельки с данным кодом:
С такой платкой удобно отлаживать свои поделки (тут и индикация и подтянутые кнопки(датчики)). В случае применения в реальном устройстве совсем не обязательно припаивать все детали, например, можно оставить два светодиода и одну кнопку.
Кнопки оказались рабочими и полезными, к покупке рекомендую.
Спасибо всем, кто дочитал этот обзор до конца, надеюсь кому-то данная информация окажется полезной.
Самые обсуждаемые обзоры
| +41 |
2493
63
|
без временных задержек с защитой от дребезга :)
Веселее будет когда потребуется отработка одновременных нажатий. Это не когда зажали шифт и получили заглавную букву, а когда кнопка А это больше, Б это меньше и вместе они энтер. Длинное же нажатие двух эскейп, а удержание по одной автоповтор в нужную сторону.
Вариантов решения — куча, все правильные по выхлопу, но с разной реализацией и нюансами.
Так что нормально у вас всё, не принмайте стёб близко к сердцу.
а одновременное нажатие вот при таком коде несложно обработать, а портянка она и не короче будет )
И да, пробовал на энкодере.
а 100к — многовато :)
ну и… задача была написать а не нарисовать )
чтобы не быть простодругом — надо быть проще
По существу: 3 кнопки и 2 диода = 7 проводов и 5 вводов/выводов. Есть возможность подумать надо сокращением портов/проводов.
А в целом — всё очень наглядно и понятно, Вам +
Кнопки на АЦП, светодиоды встречно параллельно на два порта контроллера, но так как есть общий провод, то последнее лишнее и ничего не экономит, только усложняет.
Вот только с одновременным нажатием могут быть сложности :)
связанных с занятием аналоговых пинов — а есть например только цифровые…
и светодиоды можно зажигать одновременно и кнопки нажимать )
а еще светодиодами мигать можно одновременно — а можно с разной частотой
очень в узких ситуациях это можно делать — обычно это делают в условиях крайней нехватки пинов…
я же сделал универсальную платку — которой удобно отладить простые вещи,
добавте еще разные ацп и питание, будет уж вовсе не универсально…
Но это для готовых устройств, а для прототипирования нормально
Только при таких затратах изготовления делать уж сразу 4 входа/4 выхода. Не меньше
И подключать те которые используются
У аналоговых кнопок нет одновременного нажатия
Плюс затруднительна обработка по прерываниям ( и такое бывает)
Плюс геммор с настройками констант, если я хочу другие порты аналоговые использовать например с другим источником опорного
Ну и элементарно кода больше, так что аналоговые кнопки нужны при сильной экономии портов ввода/вывода. Хотя и в этом случае есть универсальное решение — расширитель портов с I2C
* if (BT[i].changed && BT[i].state == false) — подобные вещи, извиняюсь, коробят…
if (!(a && b)) { } или if (a && b); else { }
Хотя могу предложить этим индусам вариант определения максимального из двух чисел:
надо сокращением тут думать не нужно — с точки зрения отладки — а основная цель именно такая- гораздо удобнее
спасибо
Красиво писать надо везде. И в работе, и в поделке выходного дня. Это правило хорошего тона. А такие экономы потом в дедлайн такую пургу пишут и софт с аптаймом в неделю жрет 500 метров оперативы. А потом ты убиваешь неделю на хоть какую-то оптимизацию и дальше 200 метров софтина и через месяц не набирает.
в смысле среды исполнения.
Когда приходится скакать с одного проекта на другой… Причём, разные проекты реализованы на разных микроконтроллерах — 8-ми разрядных (AVR), 16-ти разрядных (MSP430), 32-разрядных (STM32). Заказчики разные, требования у всех разные. Ещё хуже, когда в одном могучем супер-проекте используется разное оборудование на МК разной разрядности, и между этим оборудованием нужно перегонять массивы данных. Вот тут-то по неволе будешь использовать универсальные обозначения типов. Благо, компилятор GCC примерно одинаковый для всех МК и в том числе для компов.
Так что я считаю, что использование обозначений типов типа (простите за каламбур!) uint8_t — скорее благо, чем зло.
И ещё, что бы не было никому обидно. Когда я использую «общие» данные (то есть такие данные, которые создаются на одном типе МК, передаются по линиям связи с помощью других МК, а обрабатываются, скажем, на ПК), то я прибегаю к обозначениям типа, у которых в названии участвует их размер. С другой стороны, когда мне, допустим, нужно обработать какой-нибудь массив, к элементам которого я получаю доступ по индексу, то для типа переменной для индекса я использую стандартное int. В этом случае сам компилятор выбирает «родной» для вычислителя тип. (Разумеется, бывают исключения!)
Во всяком случае, у меня нет никаких проблем с выбором типов. Всё однозначно и всё понятно.
К стати! Размер байта не всегда 8 бит! (Просто погуглите ради интереса!) Я такой старый, что я помню времена, когда байт был равен 5 битам (у меня до сих пор в рабочей тетрадке вклеен тетрадный листочек с кодировкой символов этими 5 битами. Ужас! Где мы были тогда, и где сейчас находимся!). Потом как-то быстро проскочили времена 6-битных байтов, и настала пора 7-битных. А потом пошли персональные компы разных мастей и байт окончательно оформился в умах новоявленных программистов как только 8-рязрадная величина. Но это уж издержки возрастного ценза.
В общем, не судите строго!
Вы абсолютно правы в своих размышлениях, но при этом пишете так, как будто не совсем уверены в своей правоте :)
всё рядом и всё правда!
Это в итоге влияет на переносимость кода, когда «суть» процесса отлаживается к примеру вне Ардуино или наоборот будучи отлаженой на Ардуино уезжает в более взрослую среду. Да и не только Ардуино это касается.
Те, кто работает в Линуксе, знают, что по умолчанию там кодировка utf-8. А это значит, что часть символов будет 8-битовыми, а часть 16-битовыми. Это тот ещё головняк!
С кодировкой utf-8 сложно работать на низком уровне, где уделяется внимание аспекту сколько байт памяти нужно резервировать по ту или иную строковую переменную. Для сравнения, в ДОС (коддировка CP866) и в Виндовсе (кодировка CP1251) было всегда, что один символ равен одному байту (8 бит). И те эмбеддеры, которые писали программы для микроконтроллеров всегда знали сколько выделяется памяти под строки. Было очень удобно. По этой причине мне нравится Виндовс.
Но в Линуксе нельзя написать (в Си) строку «Привет» и быть уверенным, что она займёт 6 байт. Реально она займет 12 байт. Символы кириллицы 16-битные. Но в то же время, размер этой строки будет равен ровно 6 символов (6 char). С непривычки может крышу снести!
А вот слово «Hello», что в байтах, что в символах всегда будет равно 5.
Особый пиетет возникает, когда нужно писать прогу для МК, который общается с символьным ЖКИ типа WH1604 (контроллер HD44780).
Возникает законный вопрос — может быть стоит избегать разрабатывать в Линуксе проги для МК, раз тут так всё сложно? Ответ — нет! Линукс легко «переваривает» файлы как с кодировкой utf-8, так и с кодировкой CP1251.
Делается всё очень просто. Те файлы, в которых не используется строковых переменных с кириллицей, вы можете писать в родной кодировке (utf-8). А те файлы, в которых используется кириллица, вы тупо создаёте в кодировке CP1251 или C866, и просто работаете как обычно. Со временем, вы можете даже забыть какой файл у вас в какой кодировке. Всё будет открываться и компилироваться абсолютно одинаково! Вот за это я уважаю Линукс! Уважаю даже больше, чем Виндовс. В Линуксе нет сложностей, но возможностей в нём значительно больше, чем в Виндовсе. Те, кто на площадях плачется о том, что Линукс корявый, его просто не знают!
Вот только я ведь говорил не про то, что чего-то может не заработать, если не правильно сделать. Я акцентировал внимание на том, что описанные выше проблемы принципиально решаются. Причем решаются весьма элегантно и далее (по ходу работ над проектом) уже более не отвлекают разработчика.
С другой стороны, и с IDE, поддерживающими разные кодировки, могут возникать проблемы, когда, к примеру, на дисплей нужно вывести текст в одной кодировке, а в UART/USB отправить этот же текст в другой кодировке :)
Не, ну если вы конечно имели в виду что вместо uint8_t нужно писать uint_fast8_t или uint_least8_t, то прошу прощения. </>
Только-только начинаю и просто копипаст не интересно, потому и благодарю. Ибо не все тут «родились с ардуинами в руках» ( в одной уно/ в другой нано) и конечно приходится постигать.
А в целом, спасибо, ибо выпаивать кнопки из старых проектов, не самое полезное занятие (это я про себя). И лучше иметь запас по видам и типам.
typedef struct
{
KBD_STATES state;
Int8U time;
} KEYBOARD;
Возможные состояния кнопки:
typedef enum
{
KB_FREE,
KB_PROCESSED,
KB_PREPRESSED,
KB_SPRESSED,
KB_LPRESSED,
KB_SRELEASED,
KB_LRELEASED,
} KBD_STATES;
При этом можно отлавливать как нажатия, короткие и длинные, так и отпускания после них, то есть отлавливаются 4 события и после обработки тоже ставится признак обработанной. В длинном нажатии еще и ведется подсчет условного времени нажатия в тиках опроса кнопок :)
Но сама процедура опроса, конечно, занимает больше кода и вызывается таймером :)
ЗЫ: если выкинуть из структуры номер кнопки, то это сэкономит память, а отразится только на инициализации, в которой это, в общем-то, и не нужно :)
понятно, что в байт можно много пакануть — но наглядности коду это явно не прибавит )невнимательно посмотрел, тут нет упаковки — можно и так сделать — время перехода из состояния в состояние оставлять — но тут в примере их два всего
А зачем оставлять время перехода в другое состояние? Это не нужно, просто текущее состояние на данный момент — нажата, отпущена, долго нажата, отпущена после долгого нажатия, обработана :)
так чтобы понять что долго нажата, нужно момент первой смены состояния запомнить, либо задержками — что не есть гуд
Наверное, проще будет дать процесс опроса кнопки :)
switch (keyb_keys[0].state)
{
case KB_PROCESSED:
if (!KEY1_READ())
{
keyb_keys[0].state = KB_FREE;
}
break;
case KB_FREE:
case KB_SRELEASED:
case KB_LRELEASED:
if (KEY1_READ())
{
keyb_keys[0].state = KB_PREPRESSED;
keyb_keys[0].time = 0;
}
break;
case KB_PREPRESSED:
if (KEY1_READ())
{
if (keyb_keys[0].time > 6)
{
keyb_keys[0].state = KB_SPRESSED;
}
else
keyb_keys[0].time++;
}
else
{
keyb_keys[0].state = KB_PROCESSED;
keyb_keys[0].time = 0;
}
break;
case KB_SPRESSED:
if (KEY1_READ())
{
if (keyb_keys[0].time > 150)
{
keyb_keys[0].state = KB_LPRESSED;
}
else
keyb_keys[0].time++;
}
else
{
keyb_keys[0].state = KB_SRELEASED;
keyb_keys[0].time = 0;
}
break;
case KB_LPRESSED:
if (!KEY1_READ())
{
keyb_keys[0].state = KB_LRELEASED;
keyb_keys[0].time = 0;
}
else
keyb_keys[0].time++;
break;
}
немного иная логика, мне проще привязаться ко времени чем к количеству опросов, так я могу регулировать процессы в более широких диапазонах.
KEY1_READ() — это макрос у вас? в котором захардкожен номер пина который читается? :) может лучше его хранить в массиве?
Опрос и у меня привязан ко времени, так как вызывается из прерывания таймера :) В этом случае я могу гарантировать корректную обработку кнопок даже если главный цикл где-то застрял в длительной процедуре, освободится — отработает кнопку по уже готовому состоянию :)
Про комментирование наоборот учат избегать лишнего комментирования в стиле
time++; // инкрементируем время
И похоже что вам именно таких комментариев не хватает.
Коммент пишется для описания функции и внутри только в особосложном участке с подвыпердом. Ну и конечно если был поставлен костыль. Еще комментят изменения в авторском коде. Но это уже для последующих обновлений скажем так.
А каждую строчку комментировать:
//вычитаем из облагамой суммы не облагаемую
Не. Не катит. Просто именам переменных даны осмысленные названия и все быстро и ясно становится понятно с какими данными мы сейчас оперируем.
Так что просто я же говорю код надо изначально писать красиво (а не как некоторые i:=u+k-j, тогда конечно голову сломаешь что это за перенные). Потом и вопросов не будет лишних.
Но я работаю не в команде, заказчику этот код мне тоже отдавать не нужно, так что особых угрызений совести я не испытываю :)
Просто оппонент, кажется, еще штанишки с подтяжками не сменил… ;)
Временами его юзаю. Удобно.
У вас же есть косяк малька. Case… Дело в том что это медленная структура. Замените ее на if. И будет быстрее.
Не говоря уже о читаемости кода:
или
Вообще я обычно посылаю лучи ненависти за такое оформление кода, когда в одну строку стремятся впихнуть весь цикл или условие :)
и
Результат в ассемблере для switch:
Для if:
Мой склероз меня не обманул — switch переводится в аналог goto и сразу прыгает в нужную ветку, а if в каждой ветке производит сравнение с условием :)
С наскока. Когда-то читал статью (было лет 10 назад), там тонны примеров и компиляторов с замерами времени. И как итог совет не увлекаться, лучше вообще не трогать свичи.
А ваш пример:
if (1<a & а<7)
i=14
else
i+=a;
Как это будет выглядить в асме?
Частный случай так сказать.
И то что вы расписали в кучу ифов или сейсов я уместил грубо говоря в 3 строчки кода.
Тогда вынужден Вас разочаровать — во-первых Ваш пример совсем не аналогичен по результату моему примеру, а во-вторых это как раз у Вас частный случай оптимизации конкретного примера (причем с ошибкой), в жизни очень не часто получается так оптимизировать :)
Для
switch (a)
{
case 1:
i += 8;
break;
case 2:
i += 9;
break;
case 3:
i += 10;
break;
case 4:
i += 11;
break;
case 5:
i += 12;
break;
case 6:
i += 13;
break;
default:
i += 14;
}
if (0<a && а<7)
i+=14
else
{
i+=a;
i+=7;
}
Конечно данный пример справедлив только для целочисленных a. Это единственное не указанное условие.
первому так же аналогичен, только опять же я с «И» пролетел и a целочисленная.
Просто LynXzp ниже легко добрался до момента когда компилятор превратил switch из переходов в бинарное дерево. Но опять же это тоже частый случай.
Ну сравните сами сколько раз Вы пролетели в первом варианте:
Вообще совершенно разные алгоритмы по факту :) И оба не аналогичны исходному алгоритму с ифами — перепутаны действия по истинности и ложности условия.
Это общий случай. Второй общий случай свича — таблица переходов, работающая еще быстрее.
Опрашивающая функция только обрабатывает в зависимости от
номераenum, и знать ничего не знает что бывают разные нажатия, или что кнопок две, а не пять, у нее 5 событий и гори все пропадом.Если Вам известный какой-то другой случай — пожалуйста, хотелось бы услышать (без иронии).
Не callback функции, а еще проще — возврат только номера кнопки или сочетания. Обработчик прост:
Единственное что в специальных меню (калибровки) приходиться писать свой switch(key)
Правда тут у меня получается глобальное меню, может у Вас вместо этого глобальная структура состояния кнопки, но не совсем представляю себе это возможным.
Структура пункта меню:
И все было бы просто, если бы пункты выполняли только переходы между меню, но в каких-то случаях активация пункта должна вызывать редактирование параметра, причем в зависимости от условий может редактироваться тот или иной параметр. Некоторые пункты должны быть сами редактируемыми (названия). То есть отработка многих пунктов зависит от текущих условий и чтобы процедура обработки кнопок знала как именно поступить в данный момент при нажатии той или иной кнопки — она должна обладать полной информацией по текущему статусу программы. А ей это совершенно не нужно, у нее своя маленькая и узкозаточенная задача :)
В принципе, обработка кнопок и у меня происходит примерно по тому же сценарию, но в главном цикле, где есть вся полнота информации :)
Я старался сделать чтобы значение кнопок не менялось, так и пользователю проще тоже, удалось такими оставить почти все: «следующее меню», «следующая позиция», "++ / изменить", «выход» и одну сделал универсальной — указатель на вызов функции «записать/применить/выполнить/Enter». Ну а остальное тоже слегка меняется. Для принятия решения что делать по той или иной кнопке у меня достаточно данных в структуре меню, но все же некоторые «особенные» меню я вынес в отдельные подпрограммы чтобы не загромождать универсальные обработчики.
Спасибо, было интересно взглянуть. Из основных различий: указателей на функции у меня только один, все значения константны (указатели, текст и неизменяемые параметры меню) и удалось все запихнуть в EEPROM (AVR).
P.S. Еще в одной небольшой программе был у меня двумерный массив указателей на обработчики.
Первый индекс — кнопка, второй — текущее состояние. И того и того было по 6, и почти все обработчики разные. Решение оказалось хорошим. Единственное что без графического комментария ничего не понятно.
У меня не обнуляет, а просто перестает увеличивать или уменьшать по достижении пределов:
(encspd — скорость вращения энкодера, чем быстрее крутишь тем сильнее меняется значение).
У меня всегда выводится текст, так что если значение числовое, то функции, изменяющие его, заботятся о переводе его в текст. Ну и во многих местах выводится не одно значение, а два-три через разделители, а кое-где меняются и сами названия пунктов, причем меняются самим пользователем :)
Сохранение текущих настроек у меня происходит либо принудительно пользователем через меню в один из 12 (кажется) пресетов, либо автоматом по истечении 30 секунд после последних изменений — эти настройки сохраняются не в пресеты, а в дефолтный набор, который потом загружается при включении. Выход из настроек — или соответствующим пунктом меню или длительным нажатием кнопки, при этом все изменения отменяются.
Аналогично :) У меня есть стандартные функции для навигации по меню любого уровня вложенности или горизонтального расширения и отрисовки, в принципе сейчас добавить новое полностью рабочее меню — дело 5 минут, которые уйдут на задание координат пунктам :) Но некоторые меню и некоторые пункты отрисовываются особым образом, для них я в указатель drawfunc подставляю отдельные функции.
У меня все константы запихнуты в code memory, EPROM в ARM вещь редкая, к сожалению :) Все настройки и параметры так же сохраняются внутри флэши в двух последних страницах (поочередно, для увеличения ресурса). Практически все тексты у меня вынесены в отдельный файл:
Не смейтесь над именами — я в них пишу буквальную транскрипцию для максимально точного понимания что это за строка :)))
Т.к. у меня сохраняется по подтверждению, то я добавил возможность визуального просмотра некоторых измененных параметров до применения. Например коэффициент округления, пока его меняешь можно ниже наблюдать как скачут показания, выбрал нужный, нажал «применить».
Хорошая идея. У меня константы такие:
Качество ужасное, снято на скорую руку :)
На главном экране на самом деле аж три разных меню: 1 — первые две строки, 2 — оставшиеся три строки, 3 — нижняя полоса с пиктограммами. Тип меню везде один и тот же, просто первое и второе отличаются цветом значений, а третье имеет нестандартную отрисовку. Для такого «бесшовного» соединения разных меню у меня в структуре меню есть указатели *prevmenu и *nextmenu, через них курсор переходит от одного меню к другому так, как если бы это было одно меню :)
Систему работы с шрифтами тоже писал сам. Существующие не устроили по качеству и разнообразию. Тут у меня есть возможность работать как с 1-битными шрифтами для экономии флэши, так и с теми, в которых каждый пиксель кодируется 2-битным значением прозрачности. При отрисовке смешивается с фоном в соответствии с прозрачностью и шрифты выглядят гораздо более плавными и сглаженными. Выглядит отлично, но жрет место во флеши…
Нижние пиктограммы, кстати, тоже являются символами отдельного шрифта :)
Иконки у меня тоже символами, потому что на 1604 никак по-другому, но неплохо выходит, даже анимация.
С таким LCD тоже делал, на AVR, память конечно выбирал много, если не оптимизировать изображения.
Это вот результат в дебаге без всякой оптимизации:
37 КБ флэши… Плюс еще 16 КБ в начальных адресах занимает бутлоадер. А всего у контроллера 64 КБ :)
Только сейчас дошло — можно же разместить мелкий шрифт у бутлоадера по фиксированному адресу и в основной прошивке пользоваться им :) Сэкономлю целых 2 КБ флеши :)
Я так сделал просто для удобства — процедура отрисовки текста у меня отработана (с автопереносами, выравниванием по левому-правому краям, в заданных координатных окнах, есть даже возможность тегами внутри текста менять цвет/фон/подчеркивание/зачеркивание) и не нужно возиться с отдельными изображениями каждой иконки :)
главное — цена )
По цене мой вариант будет однозначно дороже, и из-за токового датчика, и микроконтроллер другой, подороже, хоть и незначительно, и дисплей, и энкодер более дорогой на 30 имп/оборот (хотя его как раз можно безболезненно заменить на более дешевый 20 имп/оборот) :) Да и плат будет две — управление и силовая/высоковольтная, ею в последние пару недель как раз занимаюсь:
Все остальное на силовой плате — сборная солянка из десятков просмотренных схем, каждая из которых прогонялась раз по 10 с изменениями в симуляторе, по результатам что-то менялось, что-то выкидывалось, что-то добавлялось… Например, я перебрал штук шесть вариантов детектора нуля, пара из которых с нуля нарисована мною, а остальные четыре — из инета, но с изменениями по экспериментам в симуляторе :)
Управляющая плата вообще полностью собственная с нуля :)
Правда, подавляющее большинство обычно не вникает глубоко в теорию :)
Дарю Вам результаты не одного дня поисков, исследований, проб — две хорошие схемы детекторов :))
В последнее время я колебался между двумя вот такими схемами:
это моя:
По параметрам — превосходная, работает в диапазоне как минимум 150-250 вольт без существенного изменения времени импульса относительно нуля, помехозащищенность хорошая, потребляет в среднем около 20 милливатт. Я ее пробовал уже и в железе, все снятые вживую осциллограммы почти не отличаются от симуляции.
это доработанная из инета:
(тут ошибка на схеме — C5 должен быть 10n, это помехозащитный конденсатор)
Помехозащищенность тоже неплохая, тоже работает как минимум от 150 до 250 вольт, но при этом от напряжения зависит ток светодиода (хоть и не очень сильно), время импульса относительно перехода через ноль во всем диапазоне тоже гуляет не больше 0.1 миллисекунды, но жрет около 180 милливатт.
Остановился на втором варианте, хоть он по параметрам и слегка уступает первому, но требует меньше деталей. А я что-то вдруг решил экономить место на плате :)))
Но дело Ваше, конечно :)
вот тут народ в выключатели резисторы со светодиодами ставит и советует на 2 Ватта лучше — и ничего
(кликабельно)
а помехи там вовсе не критичны — не тот случай, времена там иные и задачи — я думал над этим — но делайте то что делаете )
погрешность в миллисекунду — никак не скажется на результате, важно попасть в заданный интервал, это если учесть особенности трансформаторов таких, если нужна точность выше то используют постоянный ток, но для большинства бытовых задач хватает и переменного, дозируя его временем в заданном интервале — поэтому фокусы с регулировками дополнительными не дают плодов
Погрешность в миллисекунду в одну сторону может раза в полтора увеличить мощность импульса, а в другую — отнимет до 20% от имеющегося рабочего времени :)
Хм. Я сам еще не добирался до экспериментов с железом, но вообще в серьезной технической литературе, посвященной контактной сварке, пишут другое :)
при переменном токе и пропускаемой одной полуволне — у вас на графике ровная прямая )
думаю тут лучше смотреть реальную картину а не усредненные значения ввиртуального ваттметра RMS
Rms по расчетам менее 0.5 вт
И вопросец первый, ок и отмена я так понимаю пункты меню и каждый раз они описываются сами по себе? Я как-то подобное гондобил, но функциональные кнопки и диалоговые окна были описаны один раз и хранили входное значение, возвращаемое и от куда все это тело приехало и куда дальше двигаться. С одной стороны было так удобно, А потом… А потом я забыл переименовать в хлам переписанную библу по работе с экраном и обновил ее… Короче код вроде и есть, но выглядит на экране и работает все боком… Сейчас планирую все повторить, но библу экрана я уже скопировал и переименовал )))
Да, все, что выделяется курсором (кроме случая редактирования) — это стандартные пункты меню, состоящие из пары «имя + значение».
И нет, для «Сохранить» и «Отмена» во всех параметрах работают две одни и те же процедуры :)
При сохранении из отредактированного пункта меню берется новое значение и вносится в массив текущих параметров, заодно обновляются и остальные параметры, зависящие от измененного. При отмене в отредактированный пункт вписывается старое значение из структуры текущих параметров и все продолжает работать как будто ничего и не менялось :)
Но не отдать нажата, когда кнопка нажата… Это называется «кнопка отпущена».
Как пример кнопка "+". Нажал, считал первый раз нажато, в обработчике сделао +1, не скинул состояние (чтобы второй раз не было +1 по нажат), считал длинное нажатие, погнал +5 и дальше как по кайфу.
Как по мне удобно и многофункционально из коробки.
Добавим сюда вообще переопределение пинов кнопки и вообще сказка. Была кнопка скажем далее, стала кнопка "+". Со своими потребностями.
И откажитесь вы уже от свича. If. Доказано что он быстрее.
Не может if быть быстрее switch, в лучшем случае они будут равны по быстродействию, но обычно свич работает быстрее потому что не перебирает все условия, а идет сразу в нужное :)
По свичам почитайте практику.
И да и нет. Я предлагаю не выносить состояния за пределы функции обработки кнопок, только события. Нужно короткое нажатие — пожалуйста событие №1, нужно длинное — пожалуйста событие №2, нужно сочетание — пожалуйста событие №3. Но функции работы логики и знать не знают что там происходит с реальными кнопками. Для них все равно — кнопок 20 или одна с разными способами нажатия, у них 20 событий и все.
Впервые о таком слышу. Давно читал что switch может разворачиваться в бинарное дерево примерно так:
И если заранее знать что c вероятностью 99% A==1 то можно уменьшить количество сравнений. Но обработка кнопок выполняется даже не 1000 раз в секунду и таких знаний нет, так что не вижу способа оптимизации.
Но тут пишетНе представляю как, разве что прыгнет по смещению проверяемой переменной, если диапазон позволяет, а от туда выполнит код — да шикарная оптимизация.
Но я решил проверить как будет в реальности:
gcc -S -O2 $file.c -o file.o
gcc -S -Os $file.c -o file.o
Я даже не понял как switch был оптимизирован, даже отрицательные числа появились. Но я конечно поспособствовал возможности такой оптимизации — многие числа шли подряд. А if увы сильно проигрывает в скорости и в размере.
Так что спасибо, раньше я только догадывался что switch лучше, но теперь я уверен что switch гораздо лучше и по всем параметрам. Это конечно х86, но не суть, оптимизации есть и они шикарны.
Тут все зависит по итогу от компилятора. Во что он это дело превратит по итогу.
а break ни кто не забыл в кейсах?
Не будем спорить, юзайте в удовольствие )
Я назвал события чтобы не путать с кодом клавиши, хотя у меня они именуются клавиши — просто номер «виртуальной клавиши» или «номер события» на которое нужно среагировать. Они не зависят вообще никак от реальной клавиатуры. Функции работы с логикой знать не знают какая реальная клавиатура и сколько нужно держать кнопку.
Точно, из-за отсутствия break программа выродилась и соотв. оказалась короткой. Исправил ситуацию, но это никак не помогло if-ам (справа):
Здесь ярко видно то что говорил AndyBig — плюс ему в карму.
Но я решил все-таки проверить и более сложный случай для switch (диапазон значений переменной изменил):
И вот оно наше бинарное дерево! Еху-ху! Что подтверждает мою догадку об возможностях и ограничениях оптимизации swtich.
Не… я люблю объективную истину познать насколько это возможно. Объективная истина в шкриншотах. Мой субъективный об этом вывод: это как С против Ассемблера — если писать просто то C и switch быстрее, если упарываться и разворачивать бинарные деревья вручную с учетом что программист знает такое что компилятор знать не может, то if и assembler быстрее (при условии что не ошибешься).
по полу ходят — как и все )
Генерал Бурдун. «День выборов»
:)